
K8S Scheduler
개요
- 스케줄러 : 새로운 Pod를 어떤 노드에 배치할지 결정하는 역할
- 사용자가 Pod를 생성하면, 스케줄러가 적절한 노드를 찾아서 할당
스케줄링의 목적
- 특정 조건을 가진 노드에서만 실행 : NodeSelector, NodeAffinity
- 여러 조건을 만족하는 노드 중 선택 : preferredDuringScheduling
- GPU 등 장치 보유 노드 배포 : Taints, Node lable, Tolerations
- 파드 간 배치 제어 (같은 노드 / 영역) : PodAffinity, AntiAffinity
- 스케줄링 대기 제어 (명시적 대기) : schedulingGates
- 노드 직접 지정 : spec.nodeName
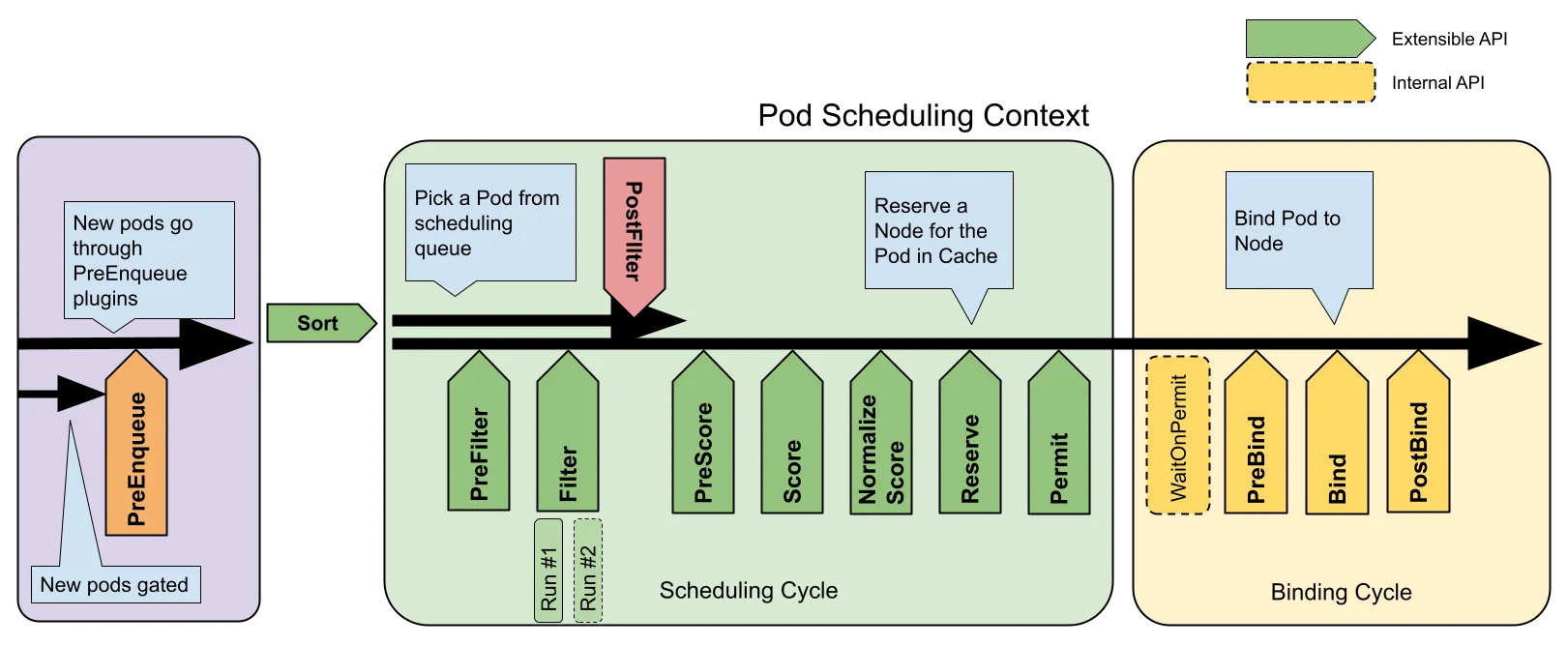

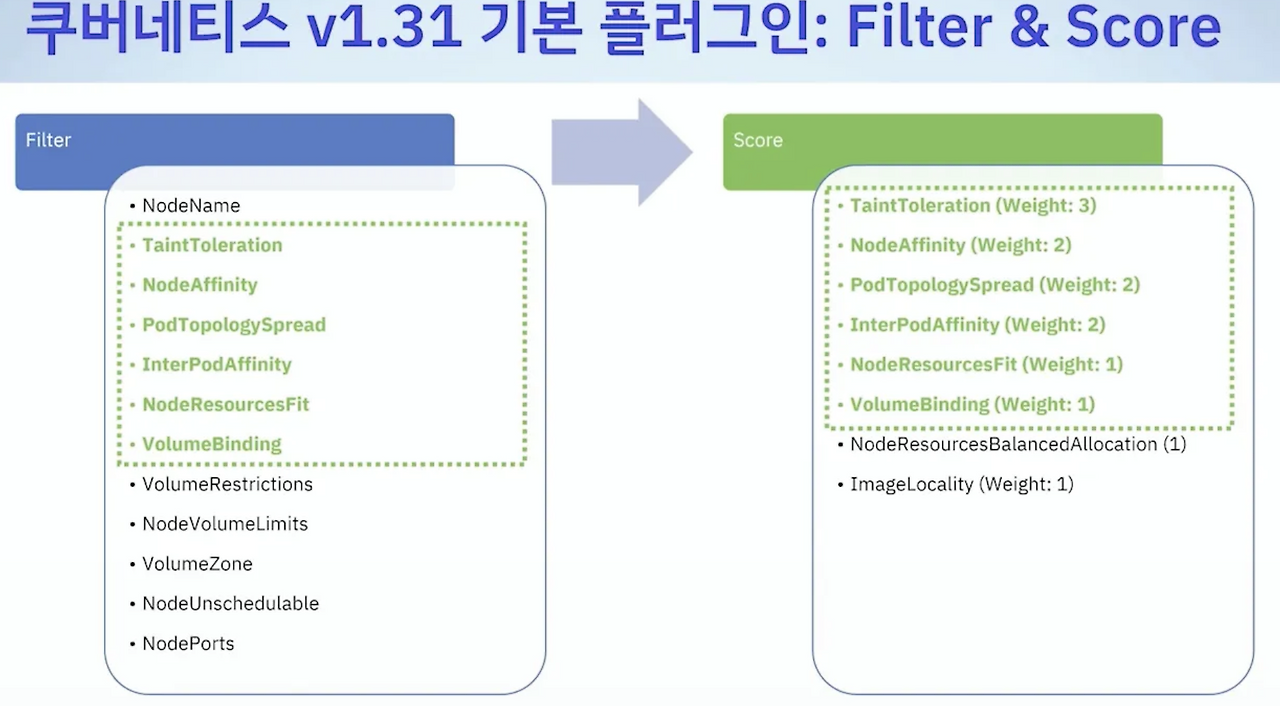
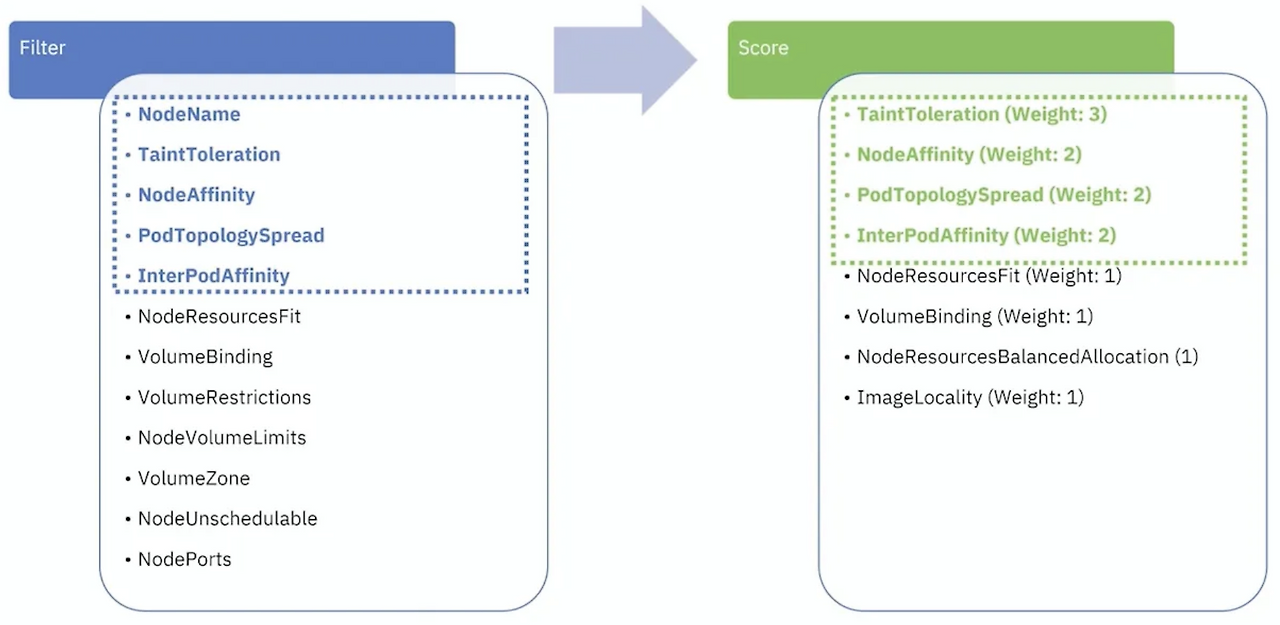
스케줄링 절차
1. 필터링 (Filtering)
- 조건에 맞지 않는 노드를 제거
- 리소스 부족 (CPU/MEM)
- NodeSelector 불일치
- taint/toleration 불일치
- v1.31부터 다양한 filter 플러그인 사용 가능
- 예: NodeResourcesFit, NodeAffinity, TaintToleration
- 대규모 클러스터일 경우 검색 대상 노드 수 제한 가능
- percentageOfNodesToScore 설정 (기본 50%, 최소 100개 또는 5%)
apiVersion: kuberschedulter.config.k8s.io/v1
kind: KubeSchedulerConfiguration
percentageOfNodeToScore: 50
2. 스코어링(Scoring)
- 필터링 통과한 노드를 대상으로 점수화
- 노드 리소스, 균형, 선호도 등
- 플러그인에 따라 점수 계산, Weight 적용
- 최종 점수가 가장 높은 노드 선택 (동점일 경우 무작위)
3. 바인딩(Binding)
- 선택된 노드에 Pod를 할당
스케줄링 제어 기능별 예시
1. NodeSelector
- 간단한 라벨 조건 지정
apiVersion: v1
kind: Pod
...
spec:
nodeSelector:
app: web
containers:
- name: nginx
image: nginx
2. NodeAffinity
- In, NotIn, Exits 등 연산자 지원
- 강제(required), 선호(preferred) 구분
apiVersion: v1
kind: Pod
...
spec:
affinity:
nodeAffinity:
requireDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- app: web
operator: In
values: [test]
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: region
operator: In
values: [kor]
3. PodAffinity / PodeAntiAffinity

- 동일 노드 또는 동일 영역 내 배치를 유도하거나 방지
apiVersion: v1
kind: Pod
...
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: [frontend]
topologyKey: "kubernetes.io/hostname"
4. Taints / Tolerations
- 노드에 taint 부여
k taint nodes gpu-node accelerator=nvidia:NoSchedule
- 해당 taint에 toleration 추가
apiVersion: v1
kind: Pod
...
spec:
tolerations:
- key: "accelerator"
operator: "Equal"
value: "nvidia"
effect: "NoSchedule"
...
5. Pod Scheduling Readiness
- v1.30부터 Stable
- 생성 시 스케줄링을 지연하고 외부 조건 충족 후 스케줄링 재개
apiVersion: v1
kind: Pod
...
spec:
schedulingGates:
- "approval.example.com/wait"
## 조건 충족 후 스케줄링 재개
k patch pod gate-pod --type=json -p '[{"op": "remove", "path": "/spec/schedulingGates"}]'
6. 명시적 노드 지정
- 스케줄러를 거치지 않고 강제로 노드 지정
apiVersion: v1
kind: Pod
...
spec:
nodeName: node-1
...
7. node label
k label nodes node-1 app=front
Fargate
Fargate?
- AWS에서 제공하는 Severless 형태의 컴퓨팅 서비스
- K8s에서는 EKS에서 Pod 단위의 서비리스 실행 환경 제공
- 인프라를 직접 관리하지 않고, 파드 단위로 컨테이너 실행 가능
Fargate의 작동 방식
- 실행단위 : EC2는 노드 단위, Fargate는 Pod 단위 실행
- 서버 관리 : EC2는 직접 관리, Fargate는 AWS 자동 관리
- 리소스 요청 : 파드 단위로 CPU/MEM 명시 필요
- 보안 : IRSA와 함께 사용 (ISMS 심사에서도 Fargate의 경우 Worker node 내부 접속 불가로 심사 대상에서 제외)
- 사용 대상 : 경량 워크로드, 단기 작업, 테스트 환경
- Cluster Autoscaler 불필요, VM 수준의 격리 가능
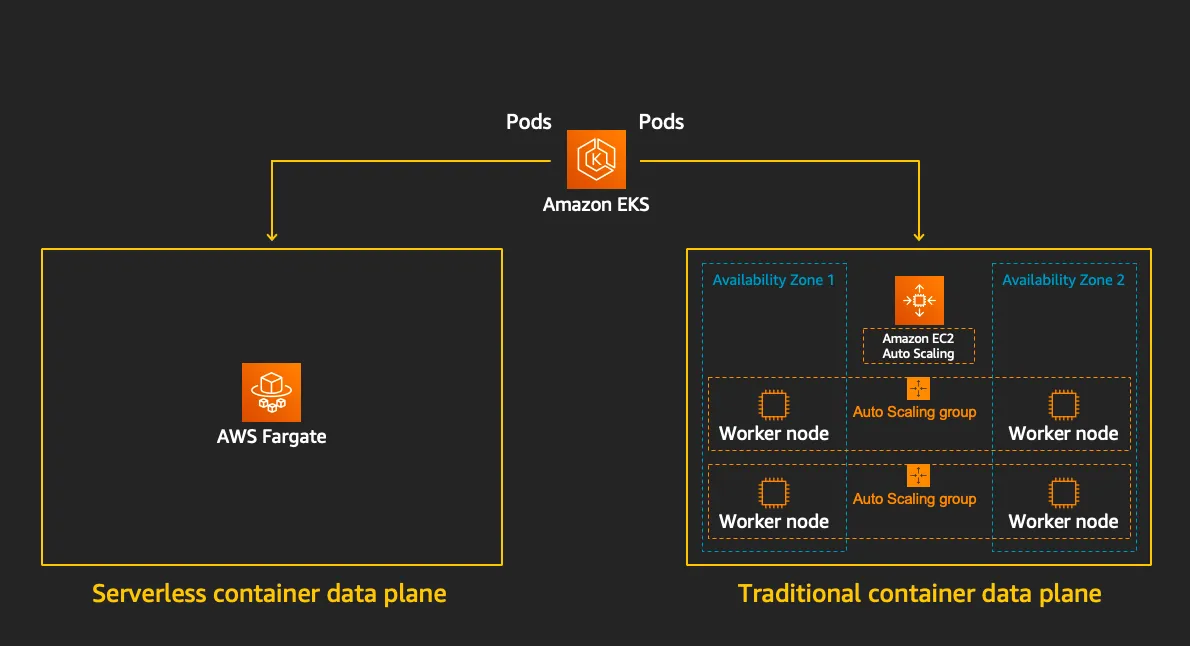
(Fargate와 EC2 EKS worker node 비교)
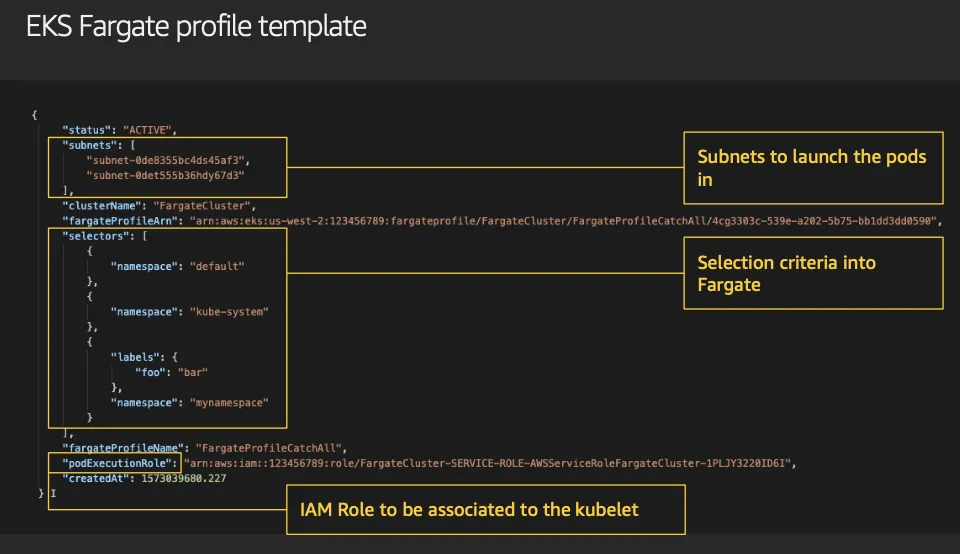
- Fargate 프로파일 (파드가 사용할 서브넷, 네임스페이스, 레이블 조건)을 생성하여 지정한 파드가 fargate에서 동작하게 함
- EKS는 스케줄러가 특정 조건을 기준으로 어느 노드에 파드를 동작시킬지 결정, 혹은 특정 설정으로 특정 노드에 파드가 동작하게 가능함
- DATA Plane
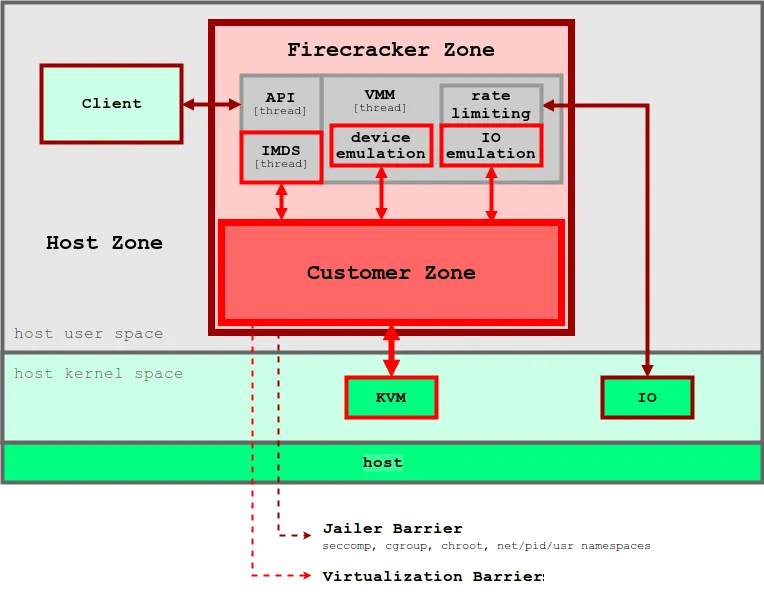
Firecracker
- Firecracker는 AWS에서 개발한 경량화 가상화 기술
- 주요 사용처 : AWS Lambda, AWS Fargate
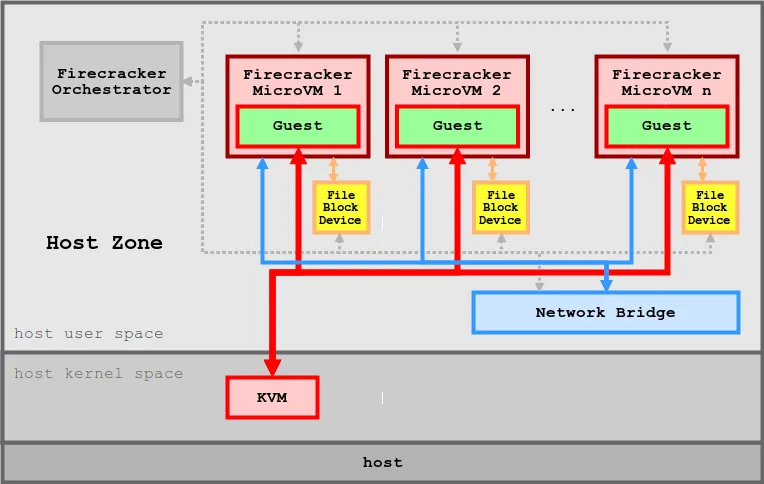
등장 배경
- 격리성 부족 : 컨테이너는 단일 커널 공유 -> 보안 취약 (ns 우회)
- 리소스 낭비 : VM은 안전하지만 무겁고 느림
- 빠른 기동 어려움 : EC2 기반 VM은 시작 / 종료 시간이 김
- 성능 / 호환성 : 컨테이너는 빠르지만 완전한 격리나 호환성 보장 어려움
Firecracker의 기술적 특성
- 기반 : KVM (Linux 커널 내장 하이퍼바이저)
- 낮은 오버헤드 : 1개의 5Mib로 동작하는 MicroVM
- 특징 : 각 VM은 독립된 커널, 파일시스템, PID/네트워크 스택 보유
- 이미지 : rootfs와 kernel 이미지를 직접 지정
- 실행 속도 : 수 sm 내에 VM 기동 가능
- 사용 방식 : REST API로 VM 생성 / 시작 / 중지
- 보안성 : jailer로 Firecracker 프로세스 자체도 격리 (Firecracker 자체를 chroot + seccomp + namespace로 보호)
AWS EKS Fargate 아키텍처 (추정 포함)
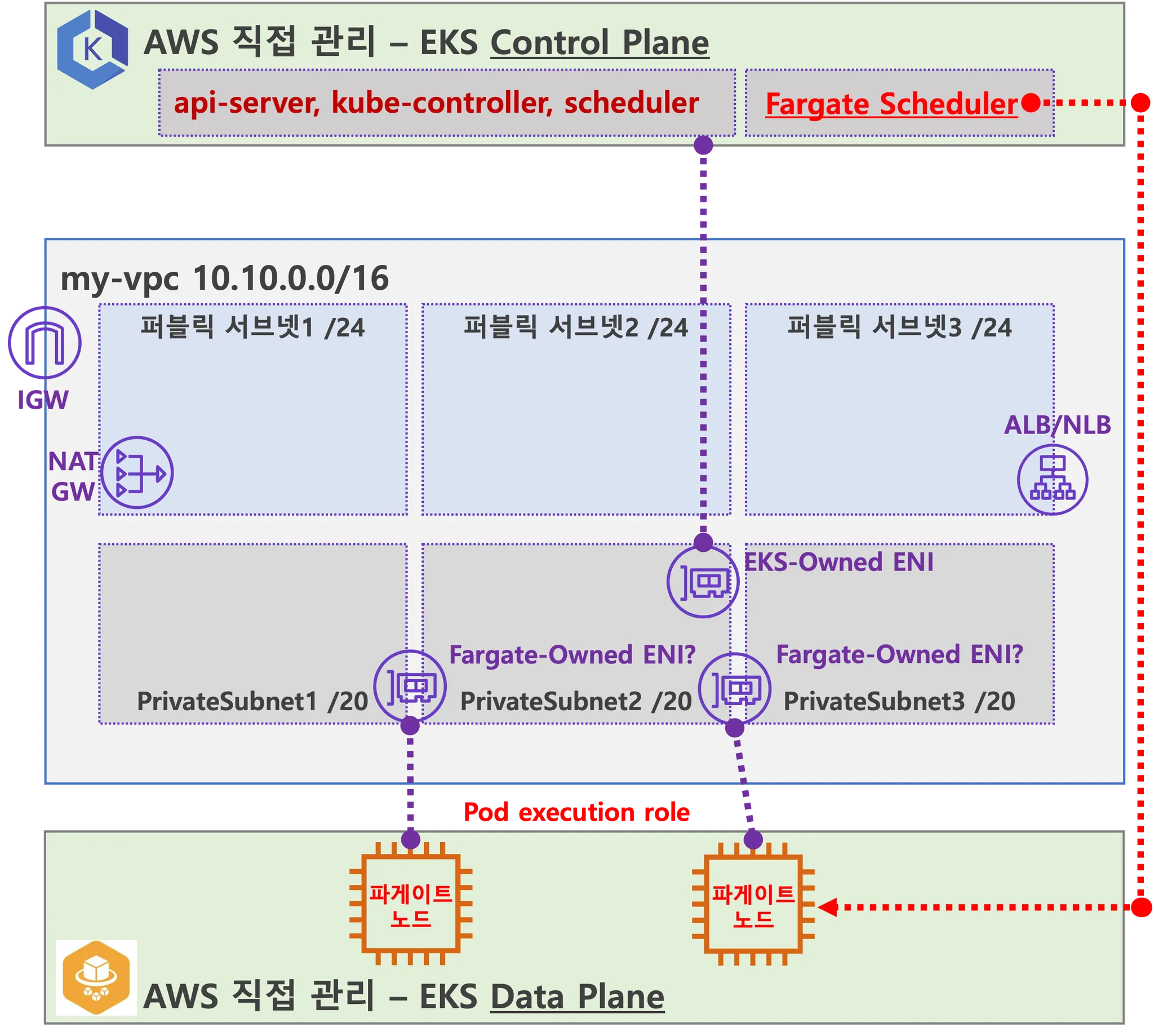
- 사용자에게 보이지 않지만, Fargate Scheduler가 EKS Control Plane에서 동작
- Fargate Scheduler에 필요한 IAM Role은 AWS가 API 호출을 수행할 수 있도록 권한을 부여하고, ECR에서 이미지를 가져오거나 CloudWatch Logs에 로그를 쓰는 등의 작업을 수행 (링크)
- Fargate에 의해서 배포된 파드(노드 당 1개 파드)에 ENI는 사용자의 VPC 영역 내에 속하여, Fargate-Owned ENI로 추정
- 파드(노드)에 필요 IAM Role은 Fargate 설치 시에 설정 필요 필요 시 파드에 IRSA 추가 설정 가능 (링크)
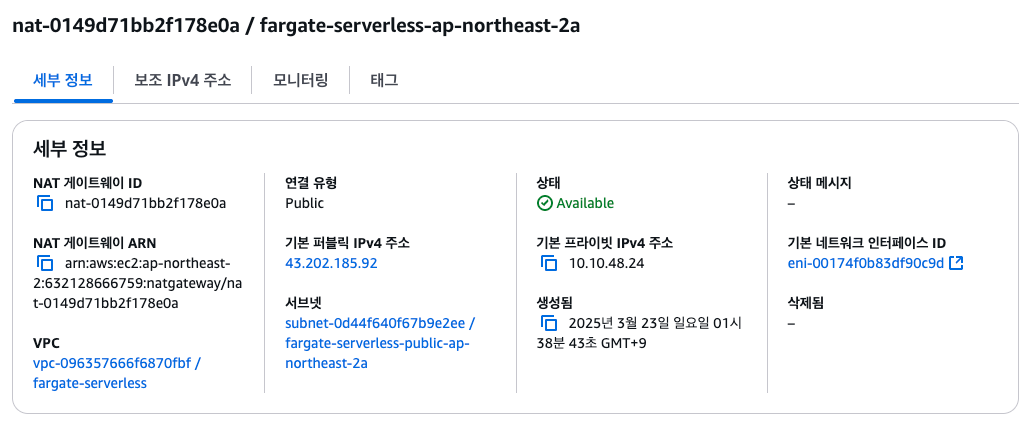
- 파드가 외부 통신 진행 시 NGW를 통해 인터넷과 통신하는 구조
- 파드가 Pub Subnet에 위치할 경우는 보안에 취약함 (링크)
- 외부에서 파드 내부로 인입 요청 시에는 -> ALB/NLB => Fargate-Owned ENI에 연결된 Fargate 파드로 전달 (링크)
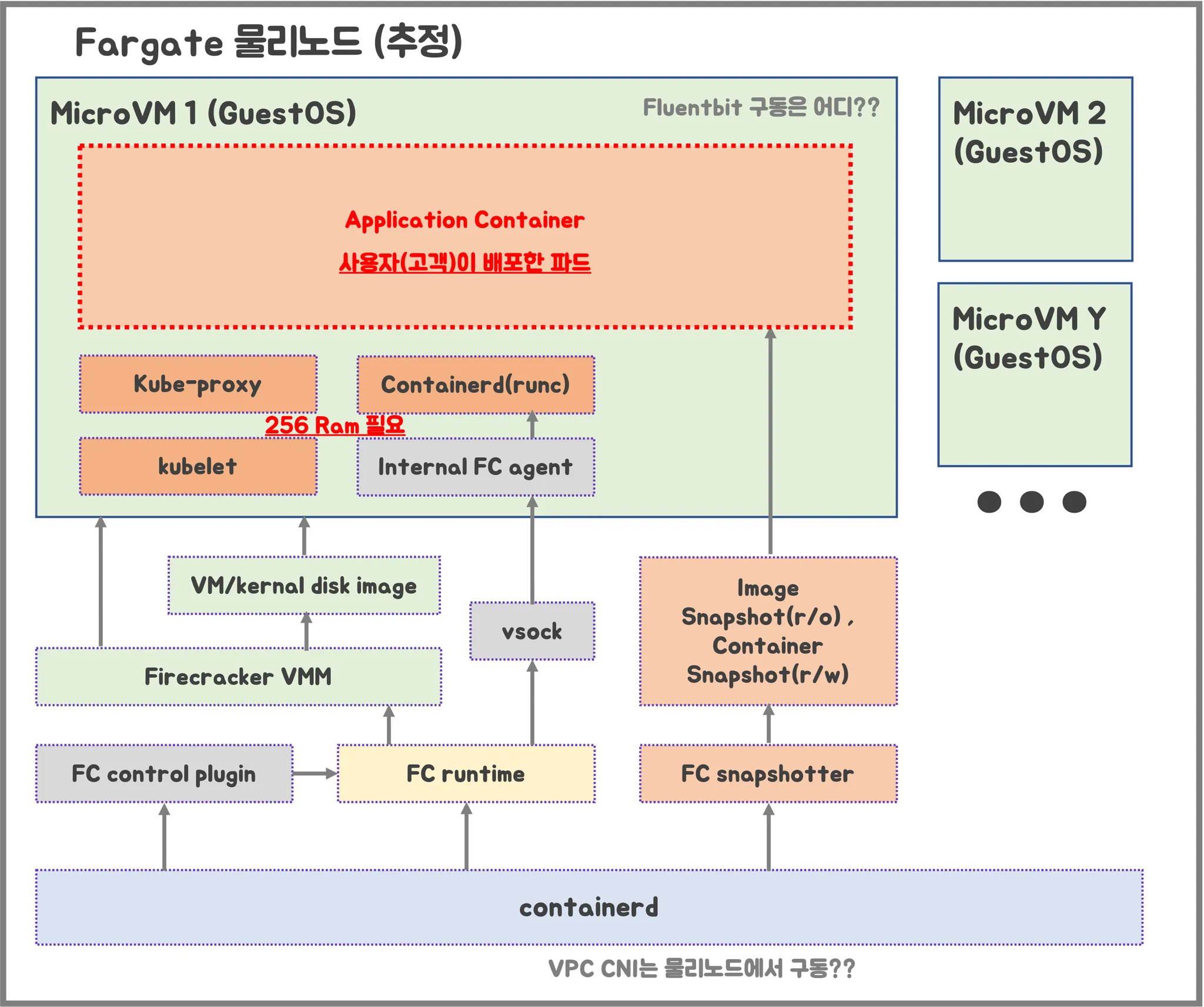
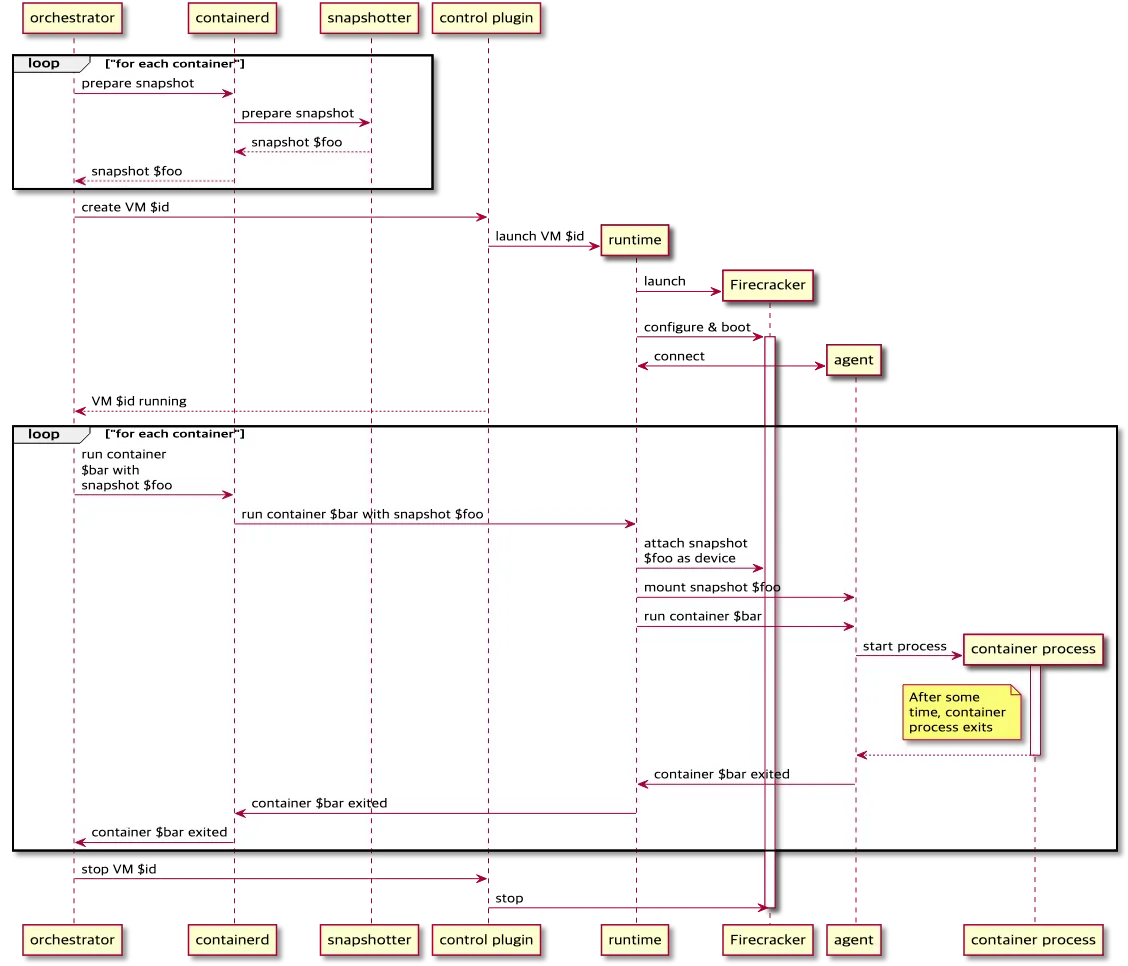
- firecracker-containerd 를 통하여 MicroVM(Application 컨테이너)를 배포.
- VMM을 통해 MicroVM을 배포하고, FC Snapshotter 를 통해서 Application Container 의 이미지를 구현.
- MicroVM 마다 Kubelet, Kube-proxy, Containerd가 동작하여, 256 RAM 반드시 필요
실습
1. Code 다운로드
git clone https://github.com/aws-ia/terraform-aws-eks-blueprints
tree terraform-aws-eks-blueprints/patterns
cd terraform-aws-eks-blueprints/patterns/fargate-serverless
2. Code 수정
(sample app 삭제, region 변경, vpc cidr 수정, namespace 변경
provider "aws" {
region = local.region
}
provider "kubernetes" {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
# This requires the awscli to be installed locally where Terraform is executed
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
provider "helm" {
kubernetes {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
# This requires the awscli to be installed locally where Terraform is executed
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
}
data "aws_availability_zones" "available" {
# Do not include local zones
filter {
name = "opt-in-status"
values = ["opt-in-not-required"]
}
}
locals {
name = basename(path.cwd)
region = "ap-northeast-2"
vpc_cidr = "10.10.0.0/16"
azs = slice(data.aws_availability_zones.available.names, 0, 3)
tags = {
Blueprint = local.name
GithubRepo = "github.com/aws-ia/terraform-aws-eks-blueprints"
}
}
################################################################################
# Cluster
################################################################################
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 20.11"
cluster_name = local.name
cluster_version = "1.30"
cluster_endpoint_public_access = true
# Give the Terraform identity admin access to the cluster
# which will allow resources to be deployed into the cluster
enable_cluster_creator_admin_permissions = true
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
# Fargate profiles use the cluster primary security group so these are not utilized
create_cluster_security_group = false
create_node_security_group = false
fargate_profiles = {
app_wildcard = {
selectors = [
{ namespace = "study-*" }
]
}
kube_system = {
name = "kube-system"
selectors = [
{ namespace = "kube-system" }
]
}
}
fargate_profile_defaults = {
iam_role_additional_policies = {
additional = module.eks_blueprints_addons.fargate_fluentbit.iam_policy[0].arn
}
}
tags = local.tags
}
################################################################################
# EKS Blueprints Addons
################################################################################
module "eks_blueprints_addons" {
source = "aws-ia/eks-blueprints-addons/aws"
version = "~> 1.16"
cluster_name = module.eks.cluster_name
cluster_endpoint = module.eks.cluster_endpoint
cluster_version = module.eks.cluster_version
oidc_provider_arn = module.eks.oidc_provider_arn
# We want to wait for the Fargate profiles to be deployed first
create_delay_dependencies = [for prof in module.eks.fargate_profiles : prof.fargate_profile_arn]
# EKS Add-ons
eks_addons = {
coredns = {
configuration_values = jsonencode({
computeType = "Fargate"
# Ensure that the we fully utilize the minimum amount of resources that are supplied by
# Fargate https://docs.aws.amazon.com/eks/latest/userguide/fargate-pod-configuration.html
# Fargate adds 256 MB to each pod's memory reservation for the required Kubernetes
# components (kubelet, kube-proxy, and containerd). Fargate rounds up to the following
# compute configuration that most closely matches the sum of vCPU and memory requests in
# order to ensure pods always have the resources that they need to run.
resources = {
limits = {
cpu = "0.25"
# We are targeting the smallest Task size of 512Mb, so we subtract 256Mb from the
# request/limit to ensure we can fit within that task
memory = "256M"
}
requests = {
cpu = "0.25"
# We are targeting the smallest Task size of 512Mb, so we subtract 256Mb from the
# request/limit to ensure we can fit within that task
memory = "256M"
}
}
})
}
vpc-cni = {}
kube-proxy = {}
}
# Enable Fargate logging this may generate a large ammount of logs, disable it if not explicitly required
enable_fargate_fluentbit = true
fargate_fluentbit = {
flb_log_cw = true
}
enable_aws_load_balancer_controller = true
aws_load_balancer_controller = {
set = [
{
name = "vpcId"
value = module.vpc.vpc_id
},
{
name = "podDisruptionBudget.maxUnavailable"
value = 1
},
]
}
tags = local.tags
}
################################################################################
# Supporting Resources
################################################################################
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "~> 5.0"
name = local.name
cidr = local.vpc_cidr
azs = local.azs
private_subnets = [for k, v in local.azs : cidrsubnet(local.vpc_cidr, 4, k)]
public_subnets = [for k, v in local.azs : cidrsubnet(local.vpc_cidr, 8, k + 48)]
enable_nat_gateway = true
single_nat_gateway = true
public_subnet_tags = {
"kubernetes.io/role/elb" = 1
}
private_subnet_tags = {
"kubernetes.io/role/internal-elb" = 1
}
tags = local.tags
}
3. terraform 배포
## 초기화
terraform init
## Dry run
terraform plan
Plan: 64 to add, 0 to change, 0 to destroy.
Changes to Outputs:
+ configure_kubectl = "aws eks --region ap-northeast-2 update-kubeconfig --name fargate-serverless"
## 배포
terraform apply
## terraform output
terraform output git:main*
configure_kubectl = "aws eks --region ap-northeast-2 update-kubeconfig --name fargate-serverless"
## EKS 자격 증명
$(terraform output -raw configure_kubectl)
## context rename
kubectl config rename-context "arn:aws:eks:ap-northeast-2:$(aws sts get-caller-identity --query 'Account' --output text):cluster/fargate-serverless" "fargate-lab"
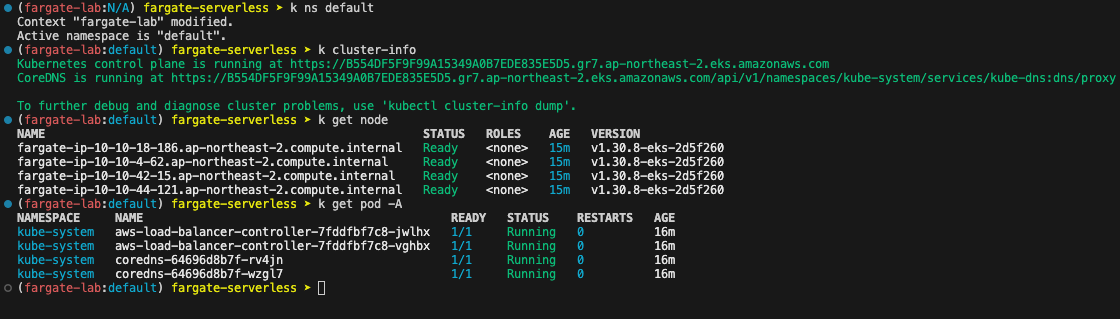
- Cluster 기본 정보 확인
- terraform 상세 정보 확인
terraform show
terraform state list
terraform state show 'module.eks.aws_eks_cluster.this[0]'
- 기본 정보 확인
## k8s api svc 확인
k get svc, ep
## 노드 정보 확인
k get csr
k get node -o wide
k describe node | grep eks.amazonaws.com/compute-type
## 파드 확인
k get pdb -n kube-system
k get pod -A -o wide
## configmap 확인
k get cm -n kube-system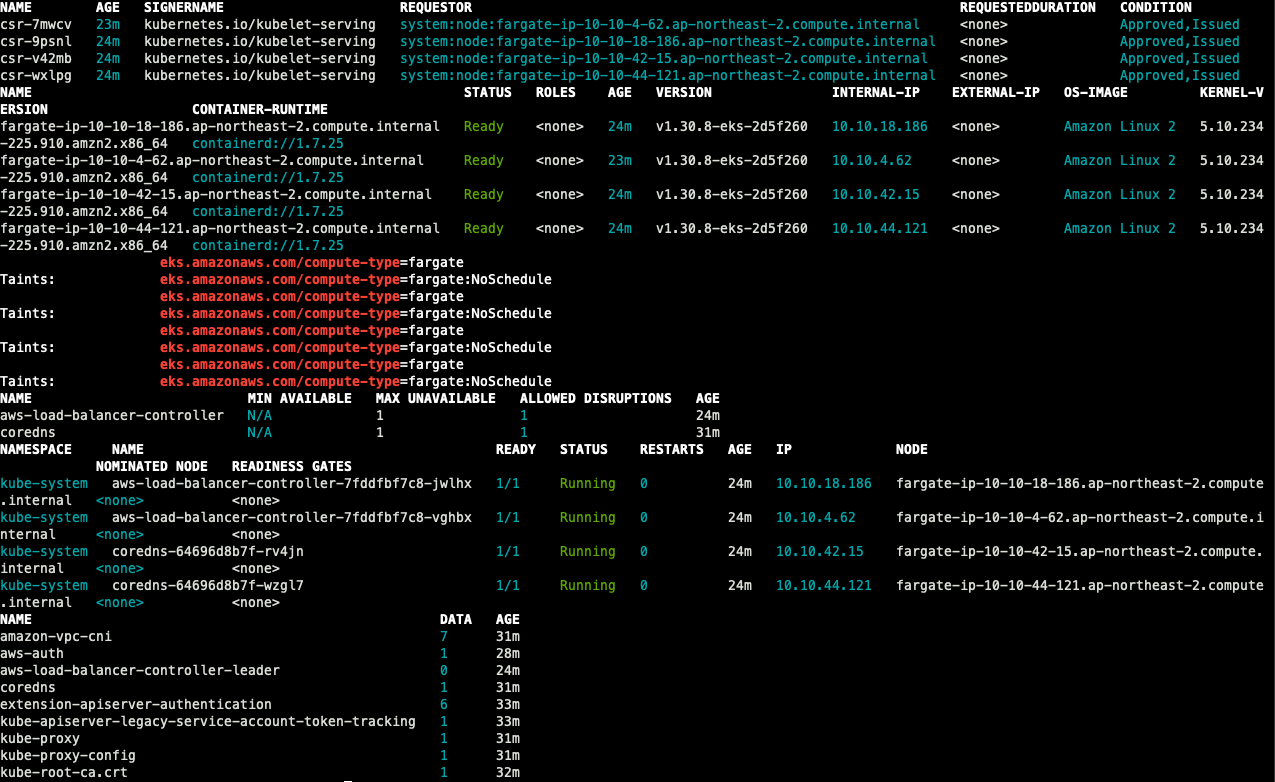
## aws-auth 보다 우선하여 IAM Access entry가 있음
# 기본 관리노드보다 system:node-proxier 그룹이 추가되어 있음
# fargate profile이 2개 인데, 그 profile 갯수만큼 있음.
k get cm -n kube-system aws-auth -o yaml
## fargate profile 확인
eksctl get fargateprofile --cluster fargate-serverless git:main*
NAME SELECTOR_NAMESPACE SELECTOR_LABELS POD_EXECUTION_ROLE_ARN SUBNETS TAGS STATUS
kube-system kube-system <none> arn:aws:iam::632128666759:role/kube-system-2025032216475532730000000f subnet-0fb7743ba258e0484,subnet-0e566d9ba1cf69706,subnet-07cd710d1aecc83c5 Blueprint=fargate-serverless,GithubRepo=github.com/aws-ia/terraform-aws-eks-blueprints ACTIVE
study_wildcard study-* <none> arn:aws:iam::632128666759:role/study_wildcard-20250322164755327400000010 subnet-0fb7743ba258e0484,subnet-0e566d9ba1cf69706,subnet-07cd710d1aecc83c5 Blueprint=fargate-serverless,GithubRepo=github.com/aws-ia/terraform-aws-eks-blueprints ACTIVE
## rbac 확인
k rbac-tool llokup system:node-proxier
## rolesum 확인
k rolesum -k Group system:node-proxier
## cni 확인
k get cm -n kube-system amazon-vpc-cni -o yaml
## coredns
k get cm -n kube-system coredns -o yaml
## 인증서 확인
k get cm -n kube-system extension-apiserver-authentication -o yaml
## kube-proxy 확인
k get cm -n kube-system kube-proxy -o yaml
k get cm -n kube-system kube-proxy-config -o yaml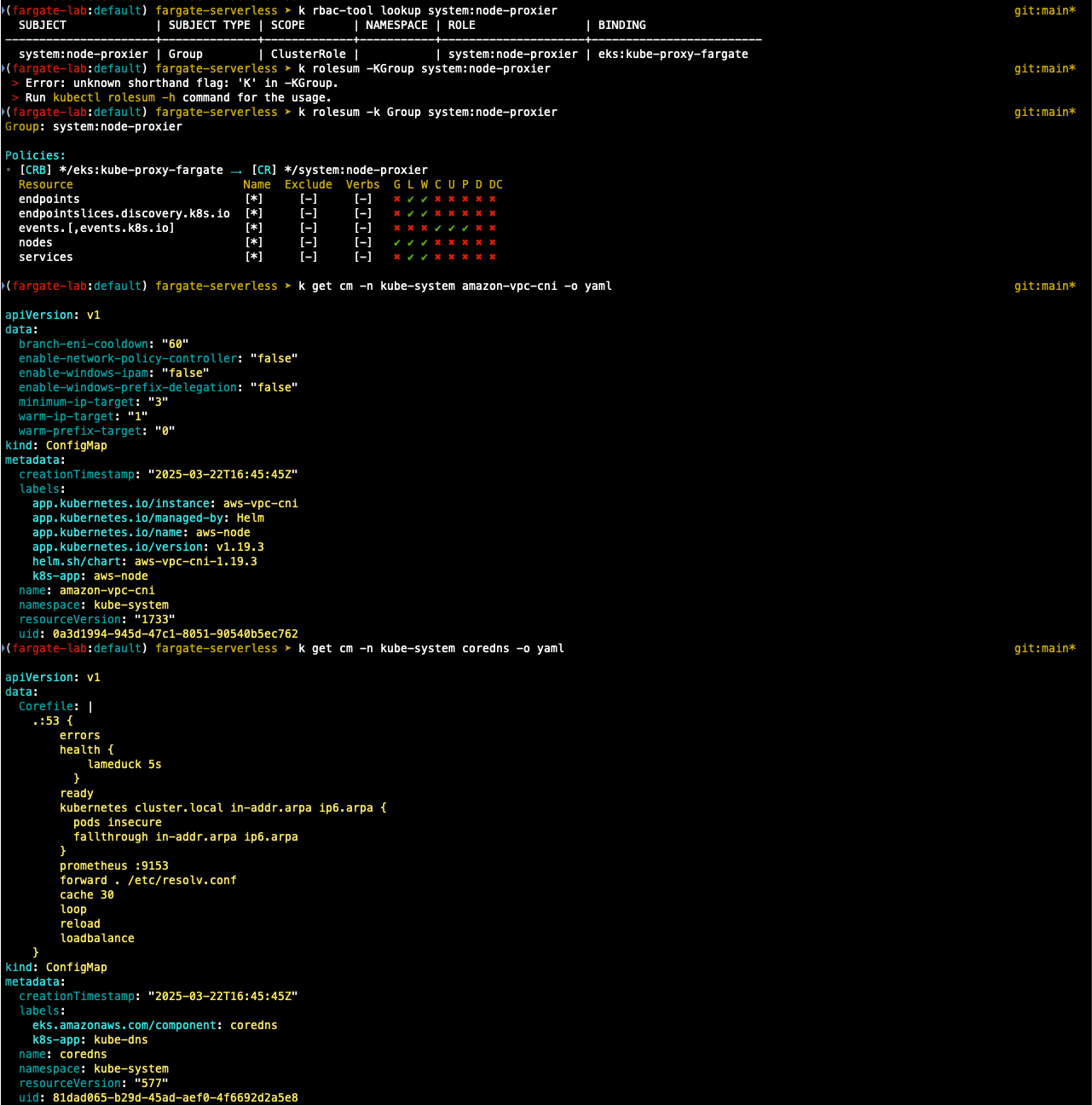
- coredns 파드 상세 정보 확인 : schedulerName: fargate-scheduler
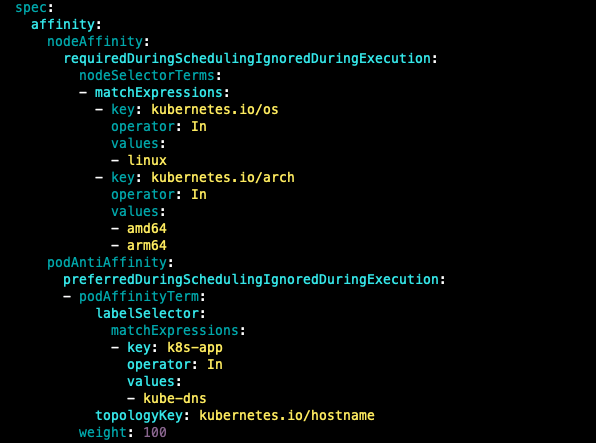
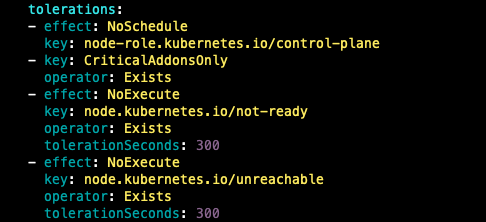
- kube-ops-view 설치
# helm 배포
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set env.TZ="Asia/Seoul" --namespace kube-system
# 포트 포워딩
kubectl port-forward deployment/kube-ops-view -n kube-system 8080:8080 &
# 접속
open "http://127.0.0.1:8080/#scale=1.5"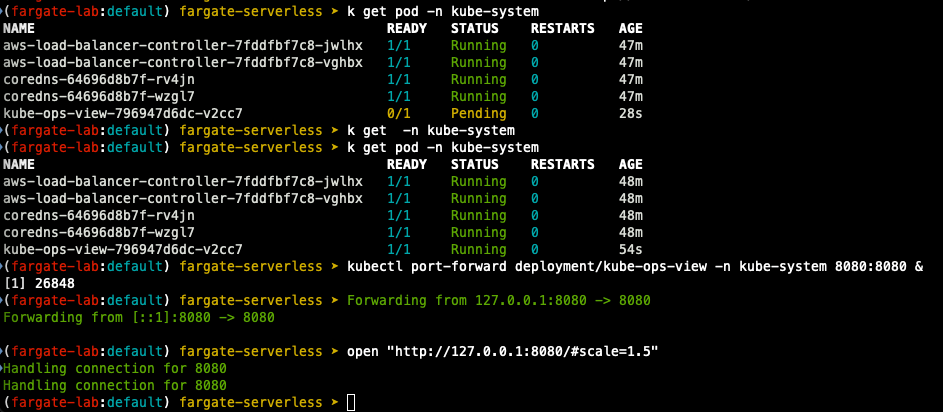
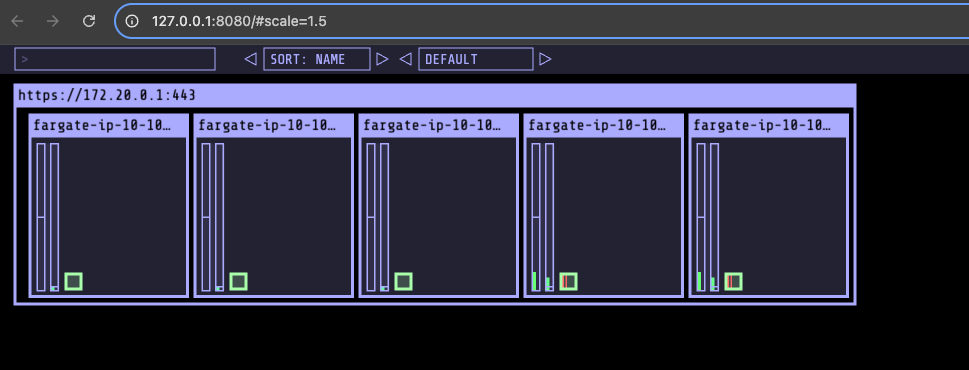
- kube-ops-view 파드 정보 확인
## node 확인
k get csr
k get node -owide
k describe node | grep eks.amazonaws.com/compute-type
## kube-ops-view deploy / pod 정보 확인
k get pod -n kube-system
k get pod -n kube-system -o jsonpath='{.items[0].metadata.annotations.CapacityProvisioned}'
k get pod -n kube-system -l app.kubernetes.io/instance=kube-ops-view -o jsonpath='{.items[0].metadata.annotations.CapacityProvisioned}'
## deploy 상세 정보
k get deploy -n kube-system kube-ops-view -o yaml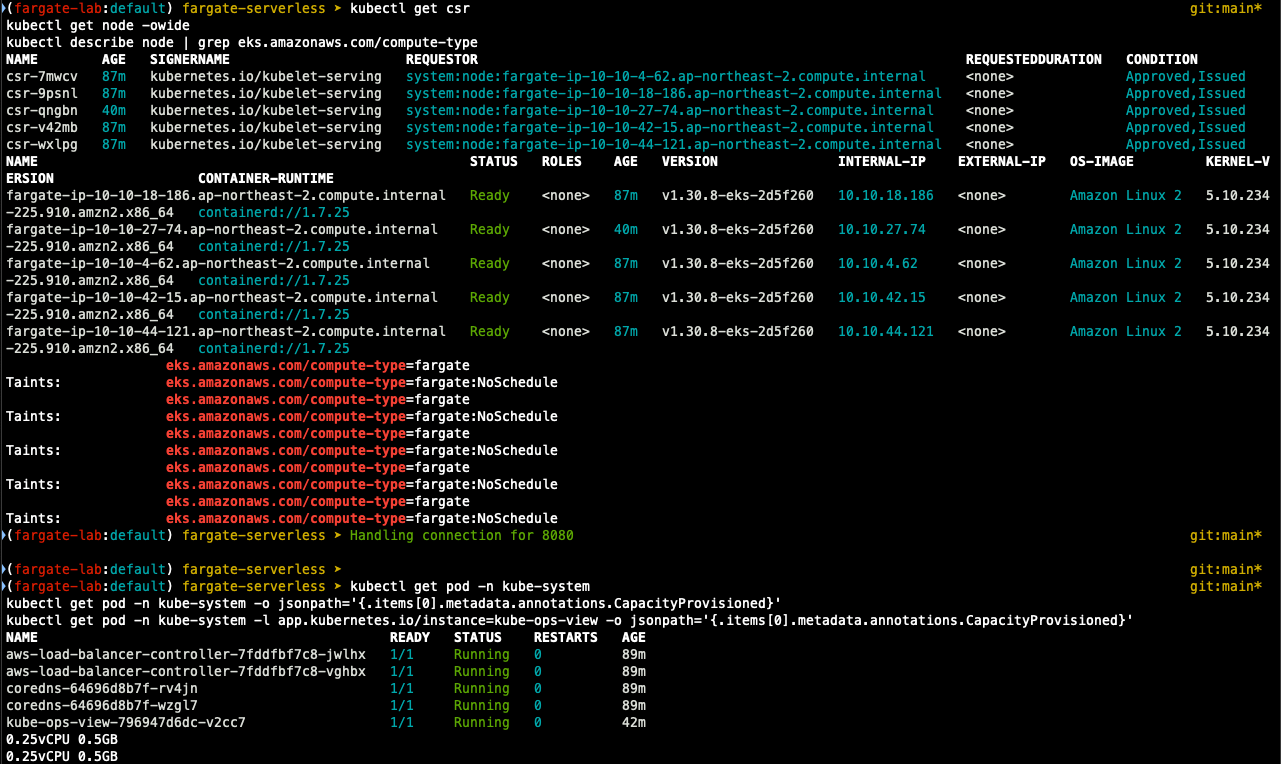
## deploy 스케줄 확인
k get deploy -n kube-system kube-ops-view -o yaml
...
enableServiceLinks: true
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: kube-ops-view
...
## 파드 상세 정보 : admission control 확인
...
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: fargate-ip-10-10-27-74.ap-northeast-2.compute.internal
preemptionPolicy: PreemptLowerPriority
priority: 2000001000
priorityClassName: system-node-critical
restartPolicy: Always
schedulerName: fargate-scheduler
...
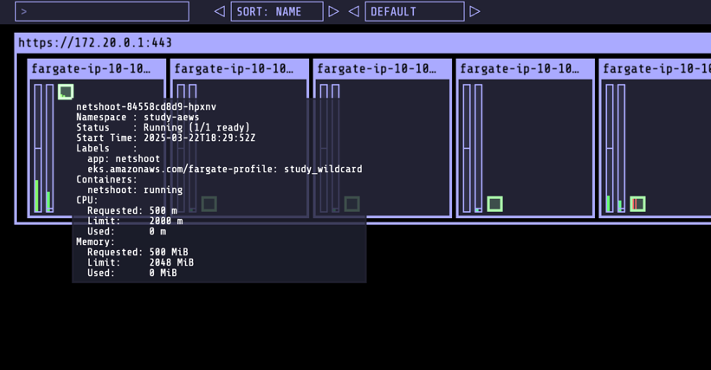
- netshoot 배포

## ns 생성
k create ns study-aews
## netshoot deploy 생성
## 0.5vCPU 1GB 할당되어, 아래 Limit 값은 의미가 없음. 배포 시 대략 시간 측정해보자!
cat <<EOF | k apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: netshoot
namespace: study-aews
spec:
replicas: 1
selector:
matchLabels:
app: netshoot
template:
metadata:
labels:
app: netshoot
spec:
containers:
- name: netshoot
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
resources:
requests:
cpu: 500m
memory: 500Mi
limits:
cpu: 2
memory: 2Gi
terminationGracePeriodSeconds: 0
EOF
##배포 시간 확인
k get events -w --sort-by '.lastTimestamp'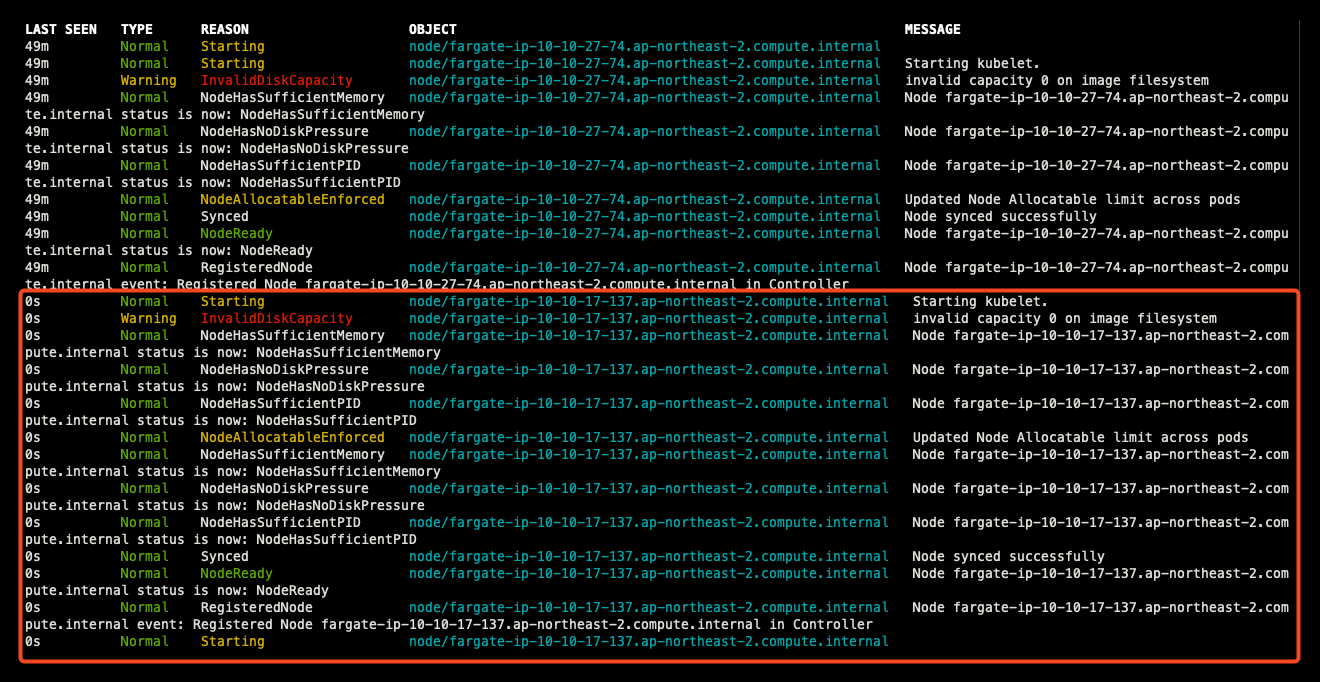
## 메모리 할당 확인
k get pod -n study-aews -o jsonpath='{.items[0].metadata.annotations.CapacityProvisioned}' git:main*
## deploy 정보 확인
k get pod -n study-aews -o yaml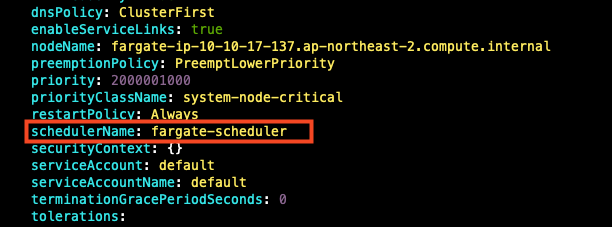

## 파드 내부에서 추가 확인
k exec -it deploy-netshoot -n study-aews -- zsh
$ ip -c a
$ cat /etc/resolv.conf
$ curl ipinfo.io/ip
$ ping -c 1
$ lsblk
$ df -hT
$ cat /etc/fstab
exit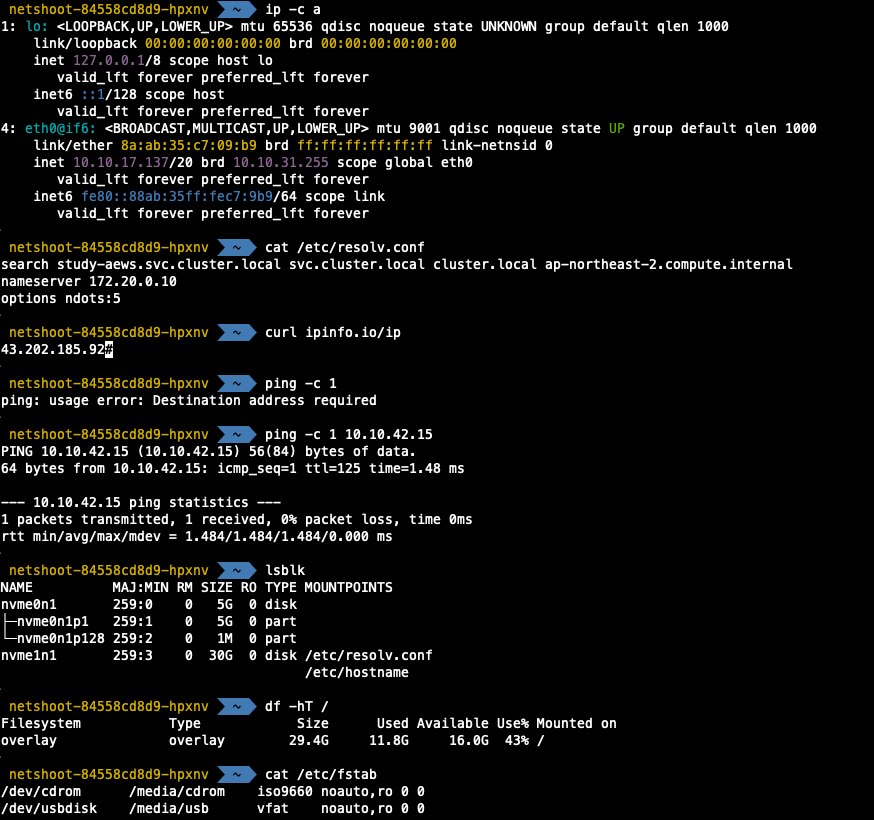
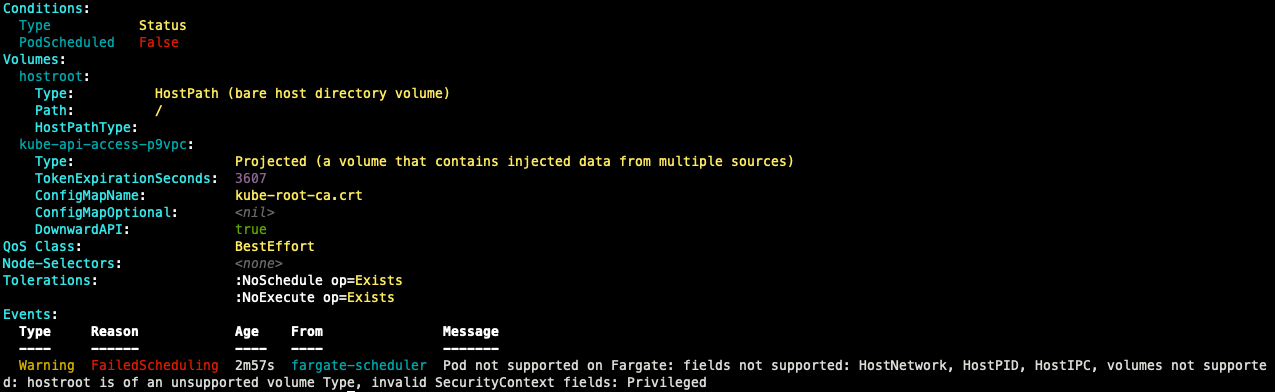
파드 권한과 호스트 네임스페이스 공유로 호스트 탈취 시도
## test pod 배포
k apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: root-shell
namespace: study-aews
spec:
containers:
- command:
- /bin/cat
image: alpine:3
name: root-shell
securityContext:
privileged: true
tty: true
stdin: true
volumeMounts:
- mountPath: /host
name: hostroot
hostNetwork: true
hostPID: true
hostIPC: true
tolerations:
- effect: NoSchedule
operator: Exists
- effect: NoExecute
operator: Exists
volumes:
- hostPath:
path: /
name: hostroot
EOF
## 파드 정보 확인
k get pod -n study-aews root-shell
k describe pod -n study-aews root-shell | grep Events: -A 10
## 삭제
k delete pod -n study-aews root-shell
생성 시 pod가 pending 상태에서 멈춰있는 것을 확인할 수 있으며, 이벤트 확인 시 fargate의 pod에서는 host 정보를 확인할 수 있는 것을 지우너하지 않고 보안 측면에서 권한 문제가 발생하는 것을 확인할 수 있다
Fargate ALB
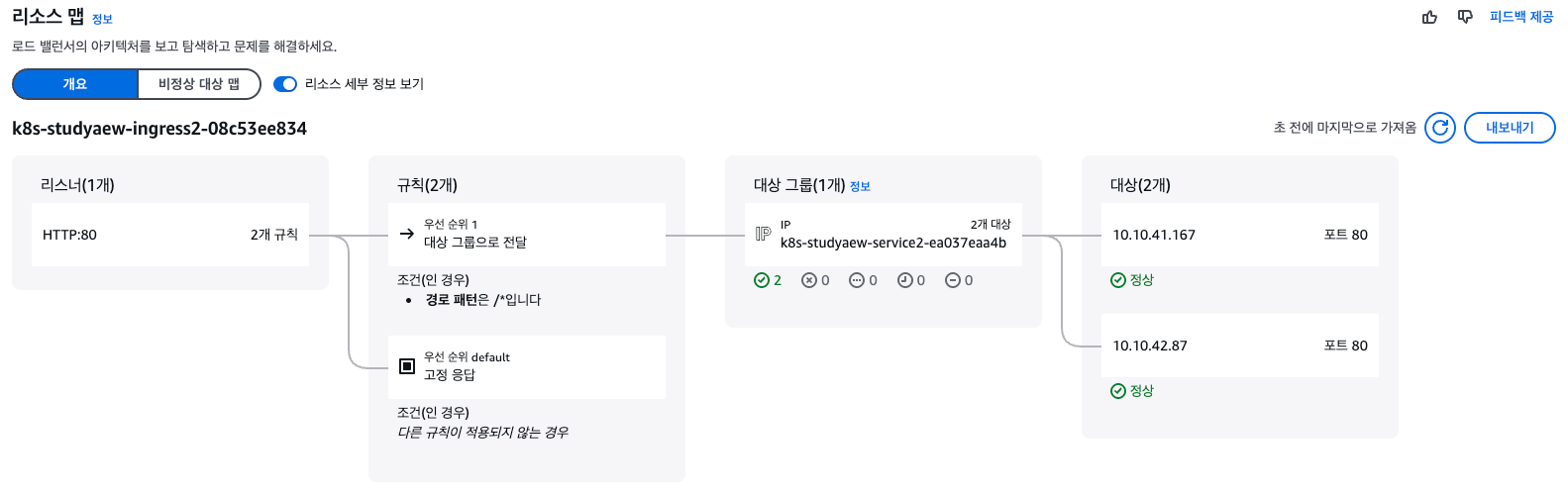
- game2048을 deploy, svc, ingress 오브젝트를 사용하여 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: study-aews
name: deployment-2048
spec:
selector:
matchLabels:
app.kubernetes.io/name: app-2048
replicas: 2
template:
metadata:
labels:
app.kubernetes.io/name: app-2048
spec:
containers:
- image: public.ecr.aws/l6m2t8p7/docker-2048:latest
imagePullPolicy: Always
name: app-2048
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
namespace: study-aews
name: service-2048
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
type: ClusterIP
selector:
app.kubernetes.io/name: app-2048
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: study-aews
name: ingress-2048
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service-2048
port:
number: 80
EOF

Fargate Job
cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:
name: busybox1
namespace: study-aews
spec:
template:
spec:
containers:
- name: busybox
image: busybox
command: ["/bin/sh", "-c", "sleep 10"]
restartPolicy: Never
ttlSecondsAfterFinished: 60 # <-- TTL controller
---
apiVersion: batch/v1
kind: Job
metadata:
name: busybox2
namespace: study-aews
spec:
template:
spec:
containers:
- name: busybox
image: busybox
command: ["/bin/sh", "-c", "sleep 10"]
restartPolicy: Never
EOF
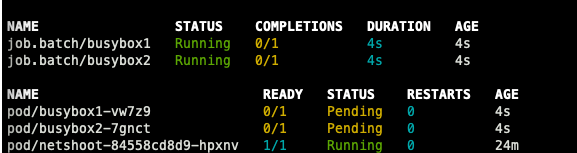
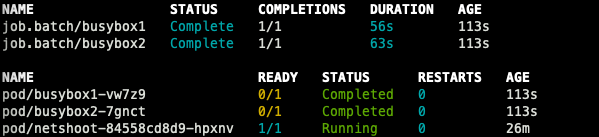
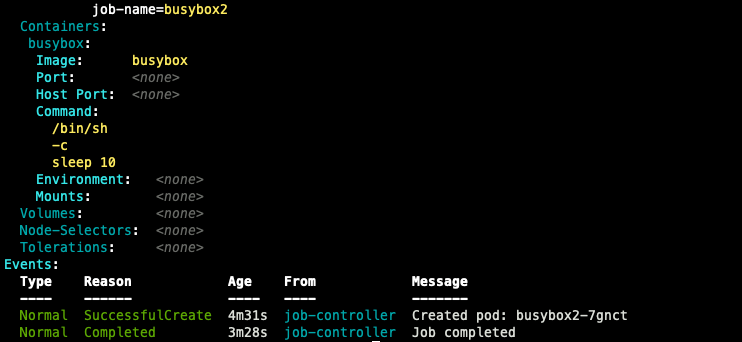
예정 job에 잘 수행된 것을 확인할 수 있다.
Fargate logging
- fargate의 eks는 fluent bit 기반의 내장 로그 라우터를 제공, Sidecar pattern을 사용하지 않고 aws에서 직접 실행
- 로그 라우터를 사용하면 ㅁws의 다양한 서비스를 로그 분석 및 저장에 사용할 수 있음
- nginx 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
namespace: study-aews
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:latest
name: nginx
ports:
- containerPort: 80
name: http
resources:
requests:
cpu: 500m
memory: 500Mi
limits:
cpu: 2
memory: 2Gi
---
apiVersion: v1
kind: Service
metadata:
name: sample-app
namespace: study-aews
spec:
selector:
app: nginx
ports:
- port: 80
targetPort: 80
protocol: TCP
type: ClusterIP
EOF
- 반복 접근 시 로그가 정상적으로 쌓이고 있는 것을 확인할 수 있음
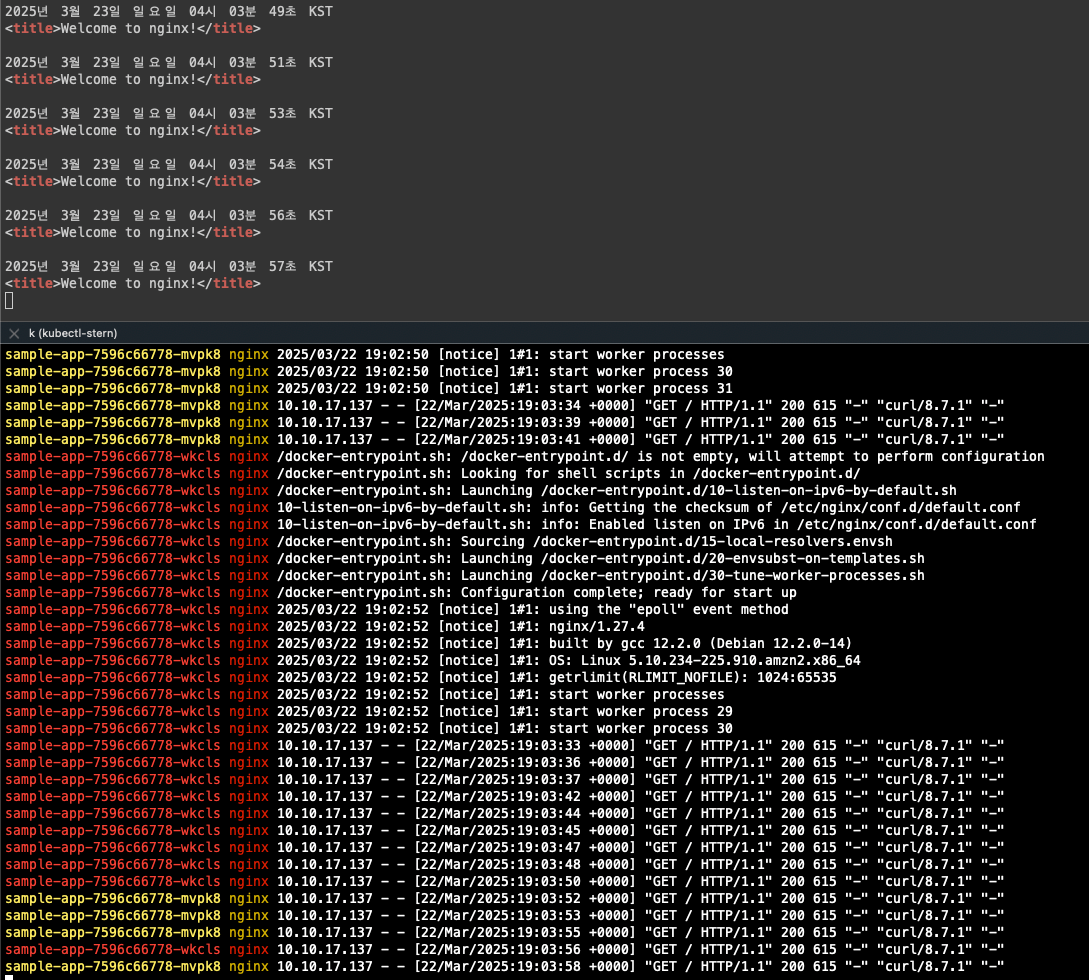
로그가 설정되는 이유는 클러스터를 배포할 때 테라폼 코드에 enable_fargate_fluentbit = true 설정되어 있기 때문이다.

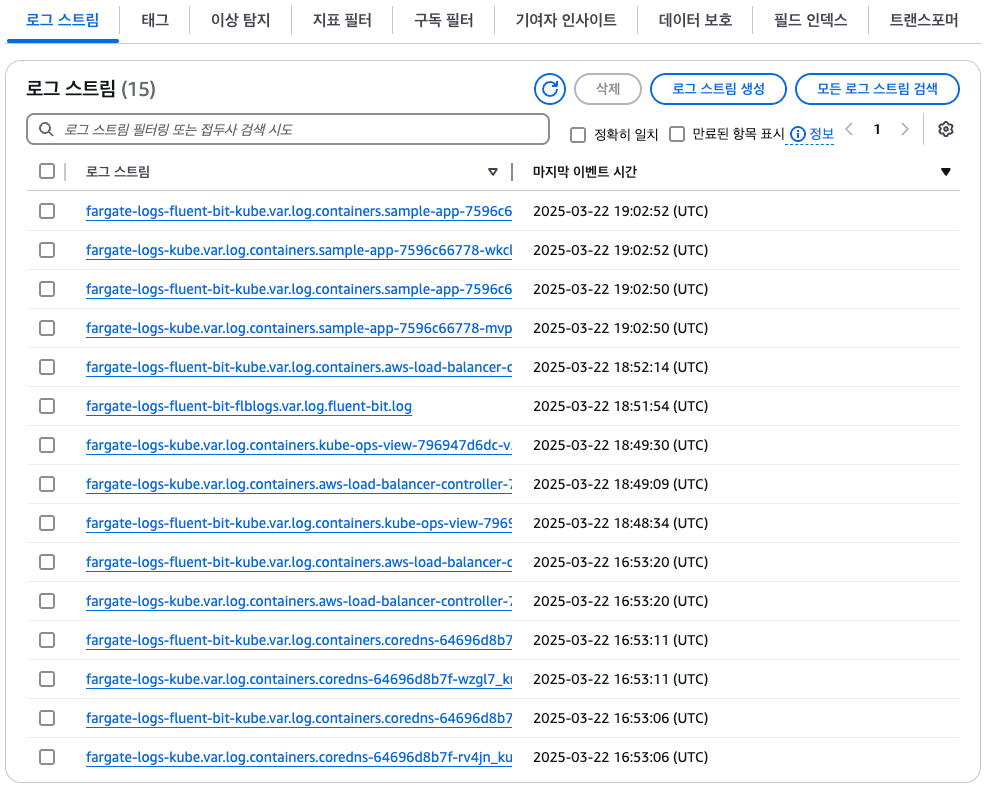
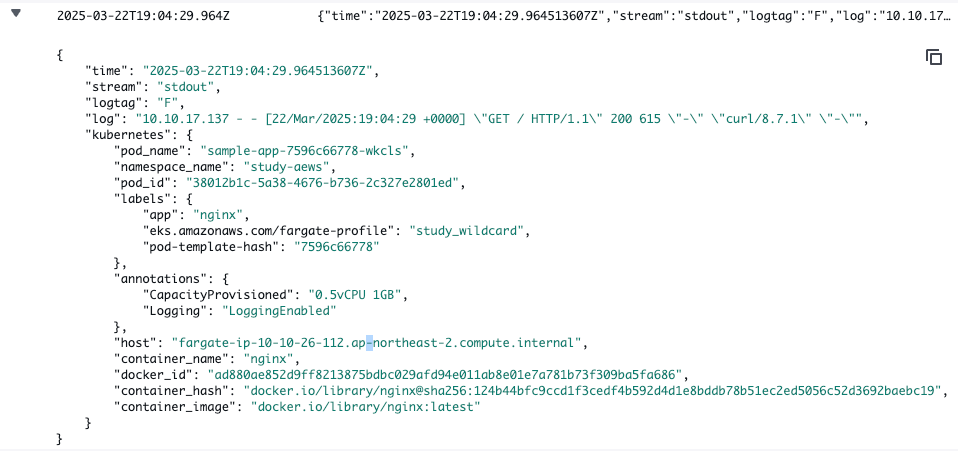
- 클러스터에서도 로그 확인
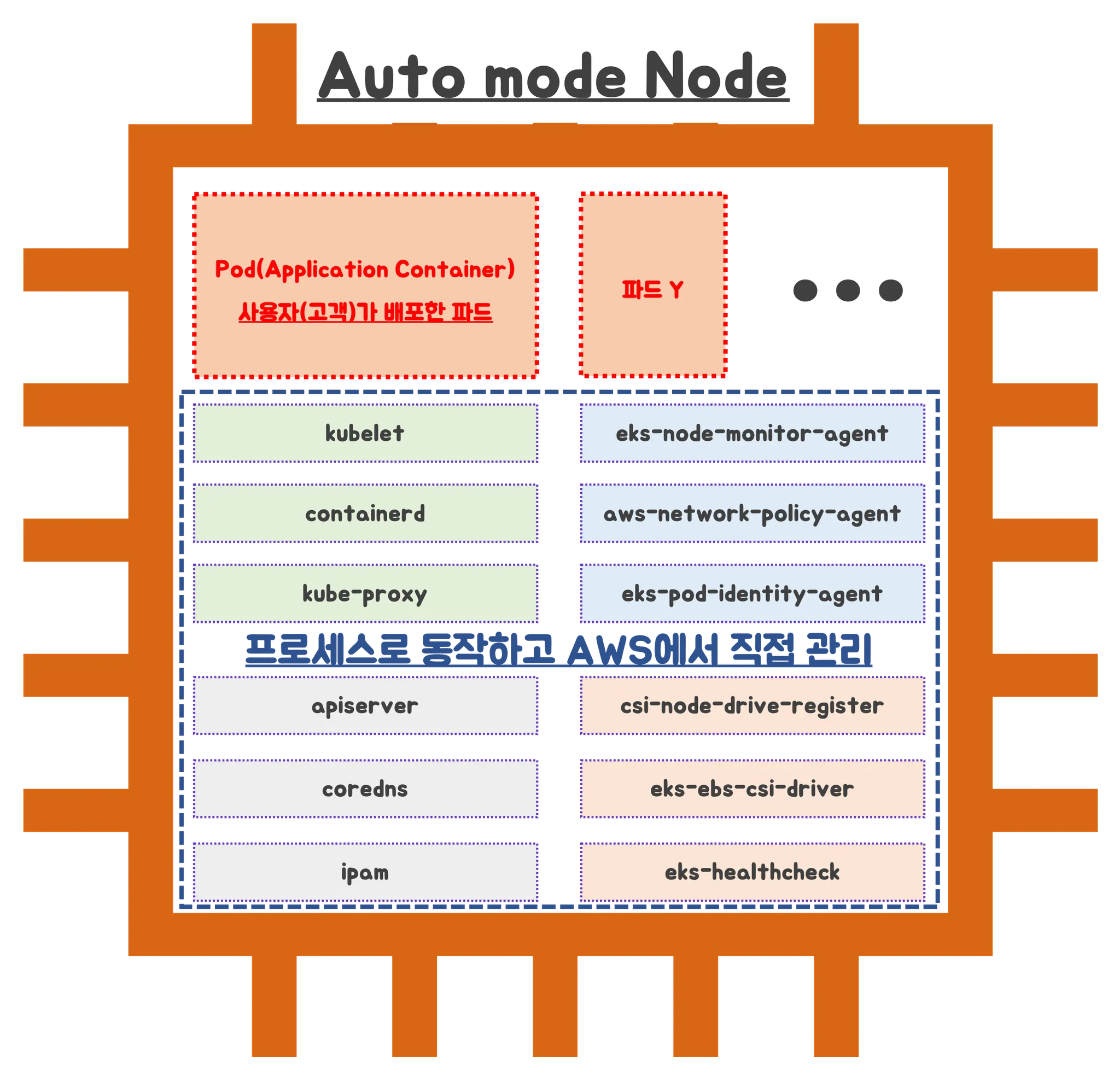
EKS Auto mode
EKS Automode는 EKSdㅔ서 자동으로 클러스터를 운영할 수 있도록 지원하는 모드입니다.
- 노드를 직접 관리하고 싶지 않을 때
- 단순 앱이나 테스트 환경 구성
- DaemonSet, GPU 등이 필요 없는 워크로드
- 보안, 격리성이 중요한 환경 (파드 단위 격리)
## Terraform 코드 clone
git clone https://github.com/aws-samples/sample-aws-eks-auto-mode.git
cd sample-aws-eks-auto-mode/terraform
## 변수 수정
region : us-east > ap-northeast-2
vpc cidr : 10.0.0.0/16 > 10.20.0.0/16
## Terraform 배포
terraform init
terraform plan
terraform apply -auto-approve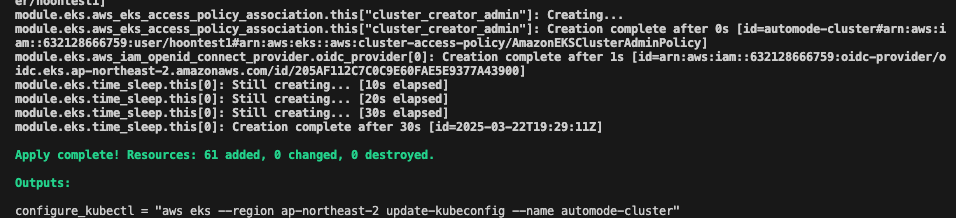
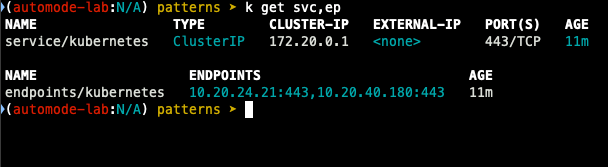

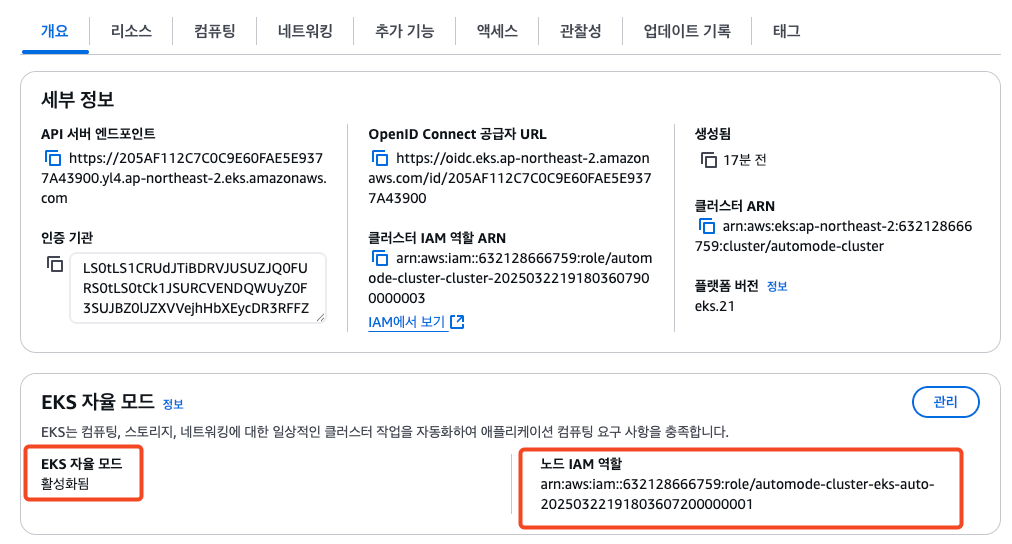
- node 관련 정보 확인
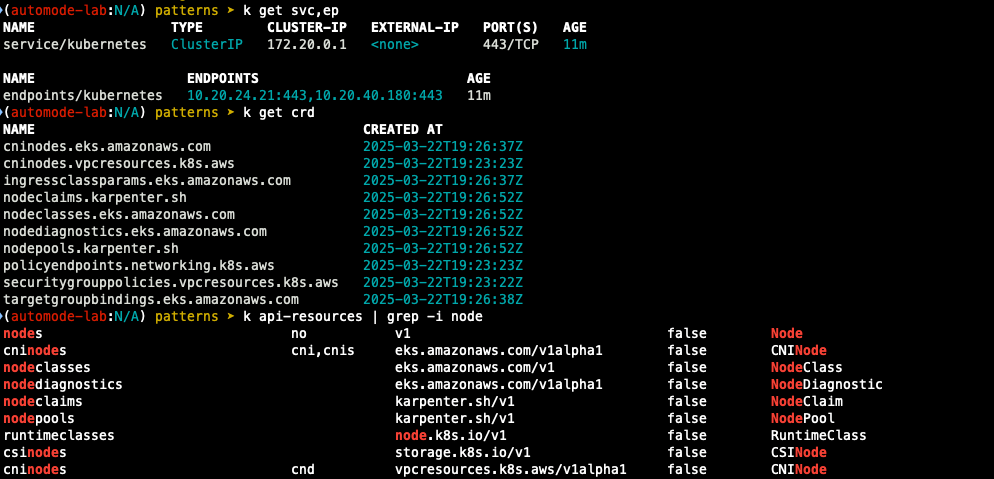
- nodeclass 확인
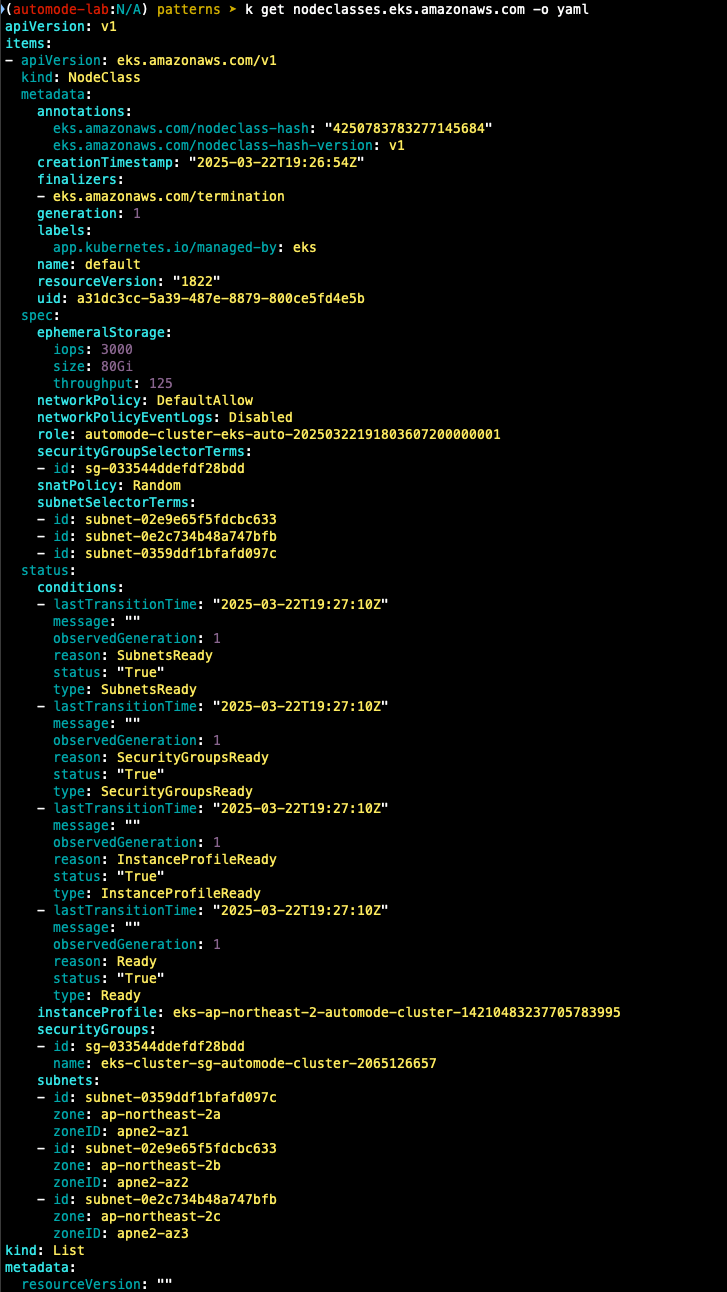
- nodepool 확인
- kube-ops-view 설치
## 모니터링
eks-node-viewer --node-sort=eks-node-viewer/node-cpu-usage=dsc --extra-labels eks-node-viewer/node-age
watch -d kubectl get node,pod -A
## 설치 확인
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set env.TZ="Asia/Seoul" --namespace kube-system
k get events -w --sort-by '.lastTimestamp'
k get nodeclaims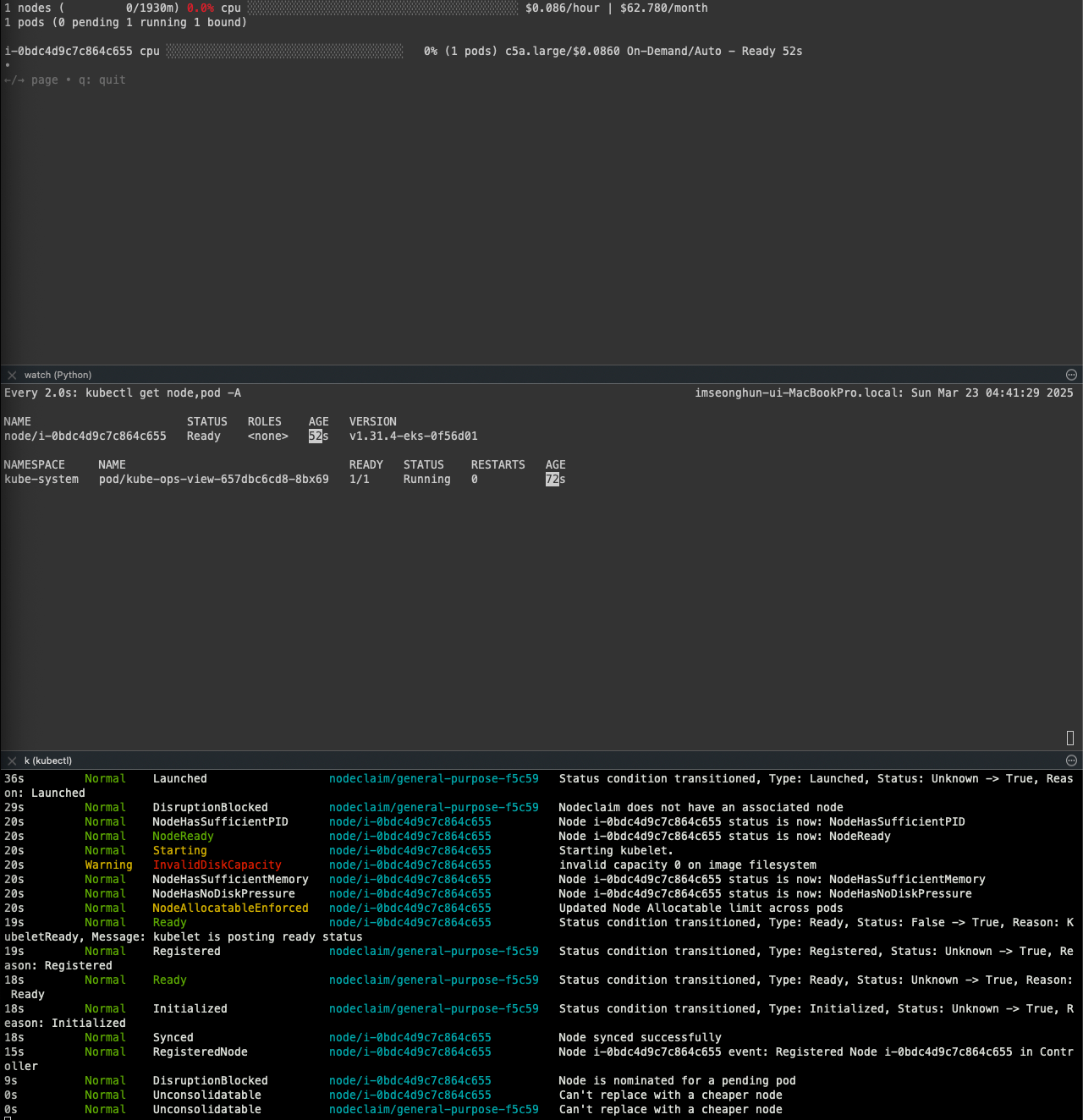


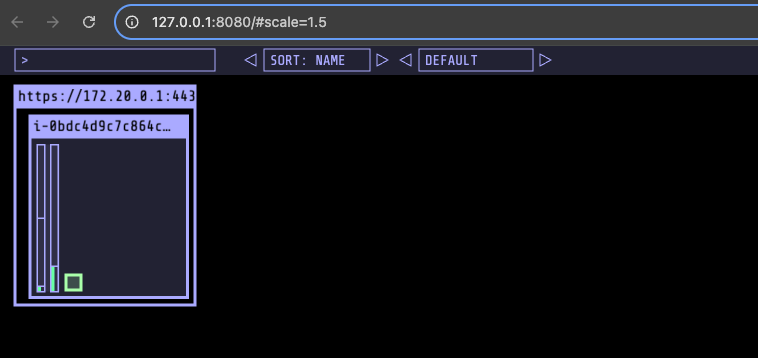
Karpenter 동작 확인
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 1
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
nodeSelector:
eks.amazonaws.com/compute-type: auto
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
securityContext:
allowPrivilegeEscalation: false
EOF
- 파드 생성 후 replicas로 scale out 동작 테스트
#
kubectl scale deployment inflate --replicas 100 && kubectl get events -w --sort-by '.lastTimestamp'
#
kubectl scale deployment inflate --replicas 200 && kubectl get events -w --sort-by '.lastTimestamp'
#
kubectl scale deployment inflate --replicas 50 && kubectl get events -w --sort-by '.lastTimestamp'
파드가 모두 노드로 스케줄링되지 못하고 karpenter가 바로 동작해 node 생성이 트리거된 것을 확인할 수 있다.
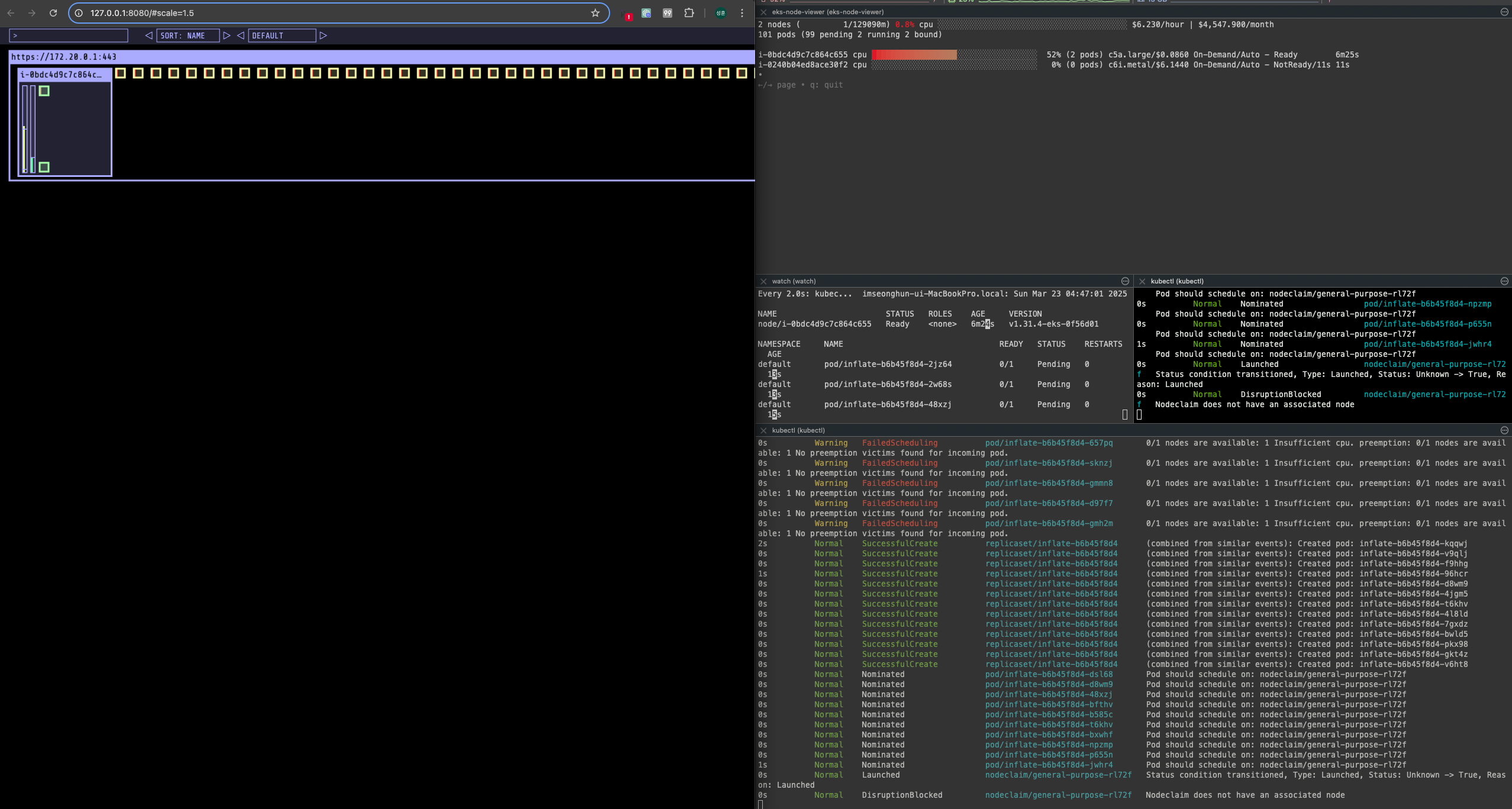
노드가 생성되고 클러스터에 조인되면 pending 상태에 있던 pod들이 node에 스케줄링 되기 시작한다.
오른쪽의 기존 노드를 보면 빨간색으로 X 표시가 되고 있는 것을 확인할 수 있다.
신규 노드가 트리거되어 생성되고 pod 스케줄링이 완료되면 이전 파드가 삭제되는 것을 확인할 수 있다.
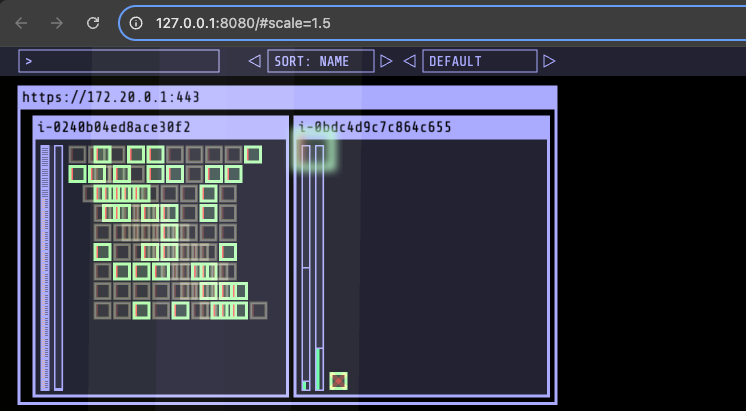
200개로 pod를 늘렸을 때에 이전과 동일하게 신규 노드가 생성되고 pending pod를 스케줄링하는 것을 확인할 수 있습니다.
단, 다른 점은 이전 노드를 삭제하고 1개 노드에 200개 파드를 스케줄링하는 것이 아니라, 2개 노드에 분산 배치하는 것을 확인할 수 있습니다.
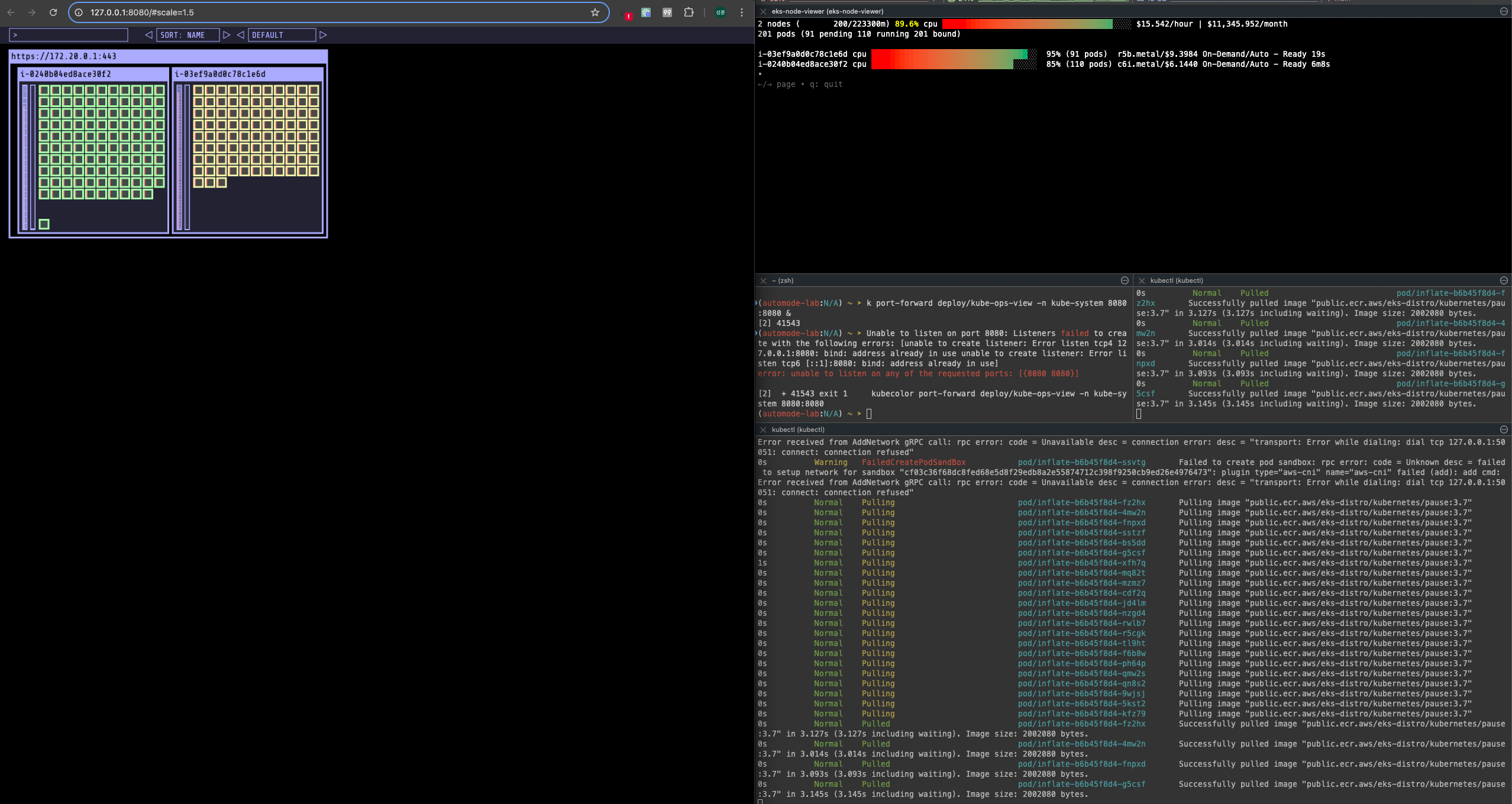
50개로 줄였을 때 Old 노드의 pod를 모두 삭제하고 old node가 삭제되는 것을 확인하였습니다.

'Cloud > AWS' 카테고리의 다른 글
| [EKS] Blue-Green Migration (0) | 2025.04.06 |
|---|---|
| [AWS] EKS Security (0) | 2025.03.13 |
| [AWS] EKS Autoscaler - Karpenter (0) | 2025.03.09 |
| [AWS] EKS Autoscaler - CPA (0) | 2025.03.09 |
| [AWS] EKS Autoscaler - CAS (0) | 2025.03.09 |
K8S Scheduler
개요
- 스케줄러 : 새로운 Pod를 어떤 노드에 배치할지 결정하는 역할
- 사용자가 Pod를 생성하면, 스케줄러가 적절한 노드를 찾아서 할당
스케줄링의 목적
- 특정 조건을 가진 노드에서만 실행 : NodeSelector, NodeAffinity
- 여러 조건을 만족하는 노드 중 선택 : preferredDuringScheduling
- GPU 등 장치 보유 노드 배포 : Taints, Node lable, Tolerations
- 파드 간 배치 제어 (같은 노드 / 영역) : PodAffinity, AntiAffinity
- 스케줄링 대기 제어 (명시적 대기) : schedulingGates
- 노드 직접 지정 : spec.nodeName
스케줄링 절차
1. 필터링 (Filtering)
- 조건에 맞지 않는 노드를 제거
- 리소스 부족 (CPU/MEM)
- NodeSelector 불일치
- taint/toleration 불일치
- v1.31부터 다양한 filter 플러그인 사용 가능
- 예: NodeResourcesFit, NodeAffinity, TaintToleration
- 대규모 클러스터일 경우 검색 대상 노드 수 제한 가능
- percentageOfNodesToScore 설정 (기본 50%, 최소 100개 또는 5%)
apiVersion: kuberschedulter.config.k8s.io/v1
kind: KubeSchedulerConfiguration
percentageOfNodeToScore: 50
2. 스코어링(Scoring)
- 필터링 통과한 노드를 대상으로 점수화
- 노드 리소스, 균형, 선호도 등
- 플러그인에 따라 점수 계산, Weight 적용
- 최종 점수가 가장 높은 노드 선택 (동점일 경우 무작위)
3. 바인딩(Binding)
- 선택된 노드에 Pod를 할당
스케줄링 제어 기능별 예시
1. NodeSelector
- 간단한 라벨 조건 지정
apiVersion: v1
kind: Pod
...
spec:
nodeSelector:
app: web
containers:
- name: nginx
image: nginx
2. NodeAffinity
- In, NotIn, Exits 등 연산자 지원
- 강제(required), 선호(preferred) 구분
apiVersion: v1
kind: Pod
...
spec:
affinity:
nodeAffinity:
requireDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- app: web
operator: In
values: [test]
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: region
operator: In
values: [kor]
3. PodAffinity / PodeAntiAffinity
- 동일 노드 또는 동일 영역 내 배치를 유도하거나 방지
apiVersion: v1
kind: Pod
...
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: [frontend]
topologyKey: "kubernetes.io/hostname"
4. Taints / Tolerations
- 노드에 taint 부여
k taint nodes gpu-node accelerator=nvidia:NoSchedule
- 해당 taint에 toleration 추가
apiVersion: v1
kind: Pod
...
spec:
tolerations:
- key: "accelerator"
operator: "Equal"
value: "nvidia"
effect: "NoSchedule"
...
5. Pod Scheduling Readiness
- v1.30부터 Stable
- 생성 시 스케줄링을 지연하고 외부 조건 충족 후 스케줄링 재개
apiVersion: v1
kind: Pod
...
spec:
schedulingGates:
- "approval.example.com/wait"
## 조건 충족 후 스케줄링 재개
k patch pod gate-pod --type=json -p '[{"op": "remove", "path": "/spec/schedulingGates"}]'
6. 명시적 노드 지정
- 스케줄러를 거치지 않고 강제로 노드 지정
apiVersion: v1
kind: Pod
...
spec:
nodeName: node-1
...
7. node label
k label nodes node-1 app=front
Fargate
Fargate?
- AWS에서 제공하는 Severless 형태의 컴퓨팅 서비스
- K8s에서는 EKS에서 Pod 단위의 서비리스 실행 환경 제공
- 인프라를 직접 관리하지 않고, 파드 단위로 컨테이너 실행 가능
Fargate의 작동 방식
- 실행단위 : EC2는 노드 단위, Fargate는 Pod 단위 실행
- 서버 관리 : EC2는 직접 관리, Fargate는 AWS 자동 관리
- 리소스 요청 : 파드 단위로 CPU/MEM 명시 필요
- 보안 : IRSA와 함께 사용 (ISMS 심사에서도 Fargate의 경우 Worker node 내부 접속 불가로 심사 대상에서 제외)
- 사용 대상 : 경량 워크로드, 단기 작업, 테스트 환경
- Cluster Autoscaler 불필요, VM 수준의 격리 가능
(Fargate와 EC2 EKS worker node 비교)
- Fargate 프로파일 (파드가 사용할 서브넷, 네임스페이스, 레이블 조건)을 생성하여 지정한 파드가 fargate에서 동작하게 함
- EKS는 스케줄러가 특정 조건을 기준으로 어느 노드에 파드를 동작시킬지 결정, 혹은 특정 설정으로 특정 노드에 파드가 동작하게 가능함
- DATA Plane
Firecracker
- Firecracker는 AWS에서 개발한 경량화 가상화 기술
- 주요 사용처 : AWS Lambda, AWS Fargate
등장 배경
- 격리성 부족 : 컨테이너는 단일 커널 공유 -> 보안 취약 (ns 우회)
- 리소스 낭비 : VM은 안전하지만 무겁고 느림
- 빠른 기동 어려움 : EC2 기반 VM은 시작 / 종료 시간이 김
- 성능 / 호환성 : 컨테이너는 빠르지만 완전한 격리나 호환성 보장 어려움
Firecracker의 기술적 특성
- 기반 : KVM (Linux 커널 내장 하이퍼바이저)
- 낮은 오버헤드 : 1개의 5Mib로 동작하는 MicroVM
- 특징 : 각 VM은 독립된 커널, 파일시스템, PID/네트워크 스택 보유
- 이미지 : rootfs와 kernel 이미지를 직접 지정
- 실행 속도 : 수 sm 내에 VM 기동 가능
- 사용 방식 : REST API로 VM 생성 / 시작 / 중지
- 보안성 : jailer로 Firecracker 프로세스 자체도 격리 (Firecracker 자체를 chroot + seccomp + namespace로 보호)
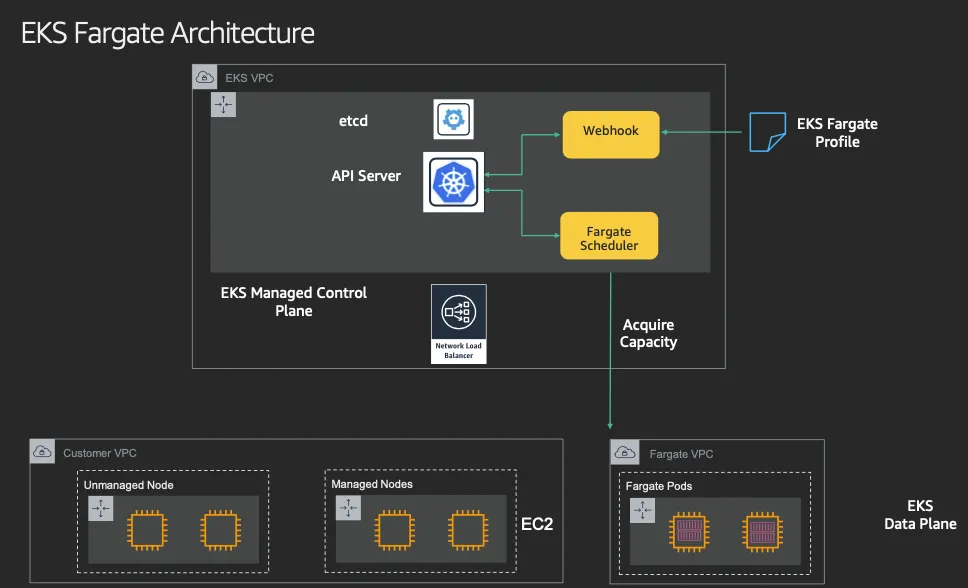
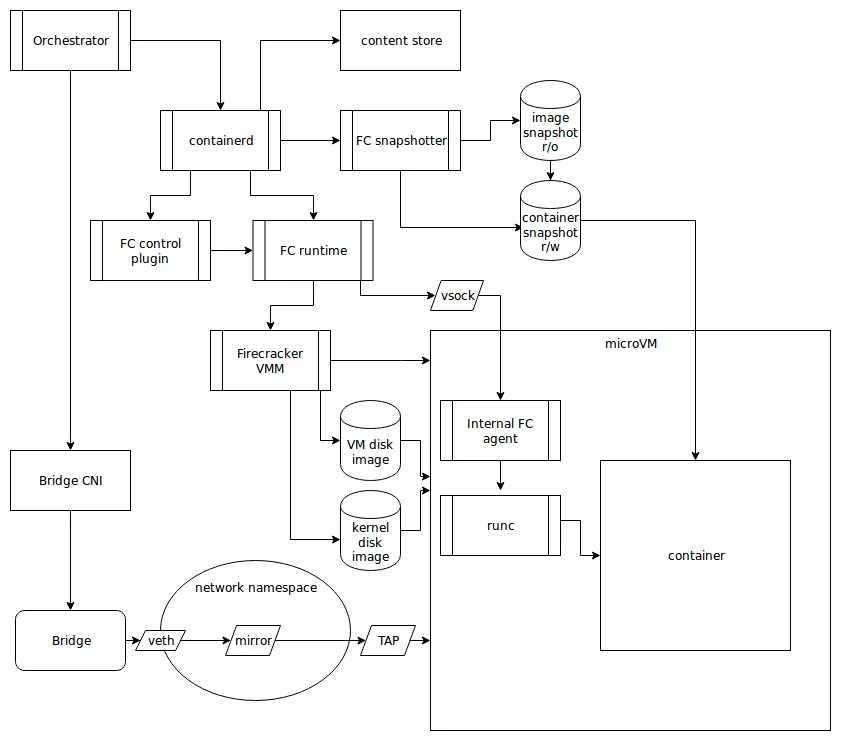
AWS EKS Fargate 아키텍처 (추정 포함)
- 사용자에게 보이지 않지만, Fargate Scheduler가 EKS Control Plane에서 동작
- Fargate Scheduler에 필요한 IAM Role은 AWS가 API 호출을 수행할 수 있도록 권한을 부여하고, ECR에서 이미지를 가져오거나 CloudWatch Logs에 로그를 쓰는 등의 작업을 수행 (링크)
- Fargate에 의해서 배포된 파드(노드 당 1개 파드)에 ENI는 사용자의 VPC 영역 내에 속하여, Fargate-Owned ENI로 추정
- 파드(노드)에 필요 IAM Role은 Fargate 설치 시에 설정 필요 필요 시 파드에 IRSA 추가 설정 가능 (링크)
- 파드가 외부 통신 진행 시 NGW를 통해 인터넷과 통신하는 구조
- 파드가 Pub Subnet에 위치할 경우는 보안에 취약함 (링크)
- 외부에서 파드 내부로 인입 요청 시에는 -> ALB/NLB => Fargate-Owned ENI에 연결된 Fargate 파드로 전달 (링크)
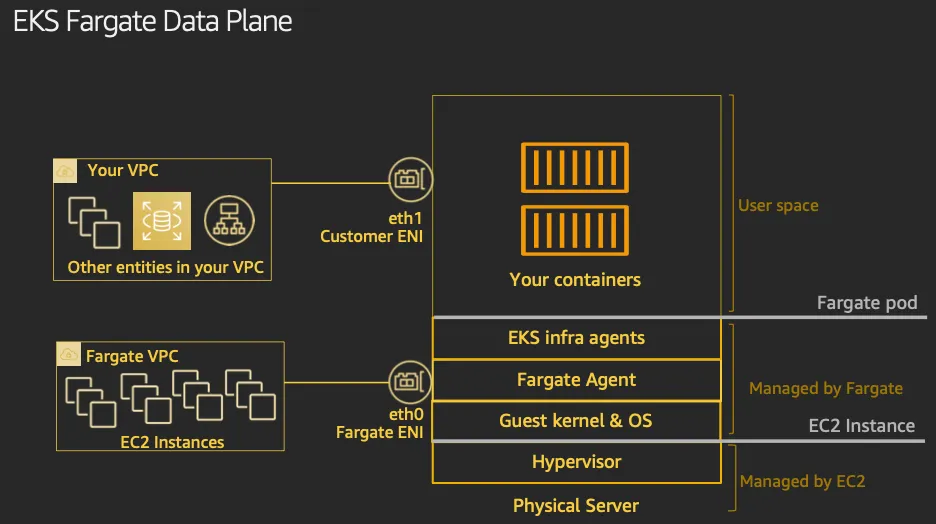
- firecracker-containerd 를 통하여 MicroVM(Application 컨테이너)를 배포.
- VMM을 통해 MicroVM을 배포하고, FC Snapshotter 를 통해서 Application Container 의 이미지를 구현.
- MicroVM 마다 Kubelet, Kube-proxy, Containerd가 동작하여, 256 RAM 반드시 필요
실습
1. Code 다운로드
git clone https://github.com/aws-ia/terraform-aws-eks-blueprints
tree terraform-aws-eks-blueprints/patterns
cd terraform-aws-eks-blueprints/patterns/fargate-serverless
2. Code 수정
(sample app 삭제, region 변경, vpc cidr 수정, namespace 변경
provider "aws" {
region = local.region
}
provider "kubernetes" {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
# This requires the awscli to be installed locally where Terraform is executed
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
provider "helm" {
kubernetes {
host = module.eks.cluster_endpoint
cluster_ca_certificate = base64decode(module.eks.cluster_certificate_authority_data)
exec {
api_version = "client.authentication.k8s.io/v1beta1"
command = "aws"
# This requires the awscli to be installed locally where Terraform is executed
args = ["eks", "get-token", "--cluster-name", module.eks.cluster_name]
}
}
}
data "aws_availability_zones" "available" {
# Do not include local zones
filter {
name = "opt-in-status"
values = ["opt-in-not-required"]
}
}
locals {
name = basename(path.cwd)
region = "ap-northeast-2"
vpc_cidr = "10.10.0.0/16"
azs = slice(data.aws_availability_zones.available.names, 0, 3)
tags = {
Blueprint = local.name
GithubRepo = "github.com/aws-ia/terraform-aws-eks-blueprints"
}
}
################################################################################
# Cluster
################################################################################
module "eks" {
source = "terraform-aws-modules/eks/aws"
version = "~> 20.11"
cluster_name = local.name
cluster_version = "1.30"
cluster_endpoint_public_access = true
# Give the Terraform identity admin access to the cluster
# which will allow resources to be deployed into the cluster
enable_cluster_creator_admin_permissions = true
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.private_subnets
# Fargate profiles use the cluster primary security group so these are not utilized
create_cluster_security_group = false
create_node_security_group = false
fargate_profiles = {
app_wildcard = {
selectors = [
{ namespace = "study-*" }
]
}
kube_system = {
name = "kube-system"
selectors = [
{ namespace = "kube-system" }
]
}
}
fargate_profile_defaults = {
iam_role_additional_policies = {
additional = module.eks_blueprints_addons.fargate_fluentbit.iam_policy[0].arn
}
}
tags = local.tags
}
################################################################################
# EKS Blueprints Addons
################################################################################
module "eks_blueprints_addons" {
source = "aws-ia/eks-blueprints-addons/aws"
version = "~> 1.16"
cluster_name = module.eks.cluster_name
cluster_endpoint = module.eks.cluster_endpoint
cluster_version = module.eks.cluster_version
oidc_provider_arn = module.eks.oidc_provider_arn
# We want to wait for the Fargate profiles to be deployed first
create_delay_dependencies = [for prof in module.eks.fargate_profiles : prof.fargate_profile_arn]
# EKS Add-ons
eks_addons = {
coredns = {
configuration_values = jsonencode({
computeType = "Fargate"
# Ensure that the we fully utilize the minimum amount of resources that are supplied by
# Fargate https://docs.aws.amazon.com/eks/latest/userguide/fargate-pod-configuration.html
# Fargate adds 256 MB to each pod's memory reservation for the required Kubernetes
# components (kubelet, kube-proxy, and containerd). Fargate rounds up to the following
# compute configuration that most closely matches the sum of vCPU and memory requests in
# order to ensure pods always have the resources that they need to run.
resources = {
limits = {
cpu = "0.25"
# We are targeting the smallest Task size of 512Mb, so we subtract 256Mb from the
# request/limit to ensure we can fit within that task
memory = "256M"
}
requests = {
cpu = "0.25"
# We are targeting the smallest Task size of 512Mb, so we subtract 256Mb from the
# request/limit to ensure we can fit within that task
memory = "256M"
}
}
})
}
vpc-cni = {}
kube-proxy = {}
}
# Enable Fargate logging this may generate a large ammount of logs, disable it if not explicitly required
enable_fargate_fluentbit = true
fargate_fluentbit = {
flb_log_cw = true
}
enable_aws_load_balancer_controller = true
aws_load_balancer_controller = {
set = [
{
name = "vpcId"
value = module.vpc.vpc_id
},
{
name = "podDisruptionBudget.maxUnavailable"
value = 1
},
]
}
tags = local.tags
}
################################################################################
# Supporting Resources
################################################################################
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "~> 5.0"
name = local.name
cidr = local.vpc_cidr
azs = local.azs
private_subnets = [for k, v in local.azs : cidrsubnet(local.vpc_cidr, 4, k)]
public_subnets = [for k, v in local.azs : cidrsubnet(local.vpc_cidr, 8, k + 48)]
enable_nat_gateway = true
single_nat_gateway = true
public_subnet_tags = {
"kubernetes.io/role/elb" = 1
}
private_subnet_tags = {
"kubernetes.io/role/internal-elb" = 1
}
tags = local.tags
}
3. terraform 배포
## 초기화
terraform init
## Dry run
terraform plan
Plan: 64 to add, 0 to change, 0 to destroy.
Changes to Outputs:
+ configure_kubectl = "aws eks --region ap-northeast-2 update-kubeconfig --name fargate-serverless"
## 배포
terraform apply## terraform output
terraform output git:main*
configure_kubectl = "aws eks --region ap-northeast-2 update-kubeconfig --name fargate-serverless"
## EKS 자격 증명
$(terraform output -raw configure_kubectl)
## context rename
kubectl config rename-context "arn:aws:eks:ap-northeast-2:$(aws sts get-caller-identity --query 'Account' --output text):cluster/fargate-serverless" "fargate-lab"
- Cluster 기본 정보 확인
- terraform 상세 정보 확인
terraform show
terraform state list
terraform state show 'module.eks.aws_eks_cluster.this[0]'
- 기본 정보 확인
## k8s api svc 확인
k get svc, ep
## 노드 정보 확인
k get csr
k get node -o wide
k describe node | grep eks.amazonaws.com/compute-type
## 파드 확인
k get pdb -n kube-system
k get pod -A -o wide
## configmap 확인
k get cm -n kube-system
## aws-auth 보다 우선하여 IAM Access entry가 있음
# 기본 관리노드보다 system:node-proxier 그룹이 추가되어 있음
# fargate profile이 2개 인데, 그 profile 갯수만큼 있음.
k get cm -n kube-system aws-auth -o yaml
## fargate profile 확인
eksctl get fargateprofile --cluster fargate-serverless git:main*
NAME SELECTOR_NAMESPACE SELECTOR_LABELS POD_EXECUTION_ROLE_ARN SUBNETS TAGS STATUS
kube-system kube-system <none> arn:aws:iam::632128666759:role/kube-system-2025032216475532730000000f subnet-0fb7743ba258e0484,subnet-0e566d9ba1cf69706,subnet-07cd710d1aecc83c5 Blueprint=fargate-serverless,GithubRepo=github.com/aws-ia/terraform-aws-eks-blueprints ACTIVE
study_wildcard study-* <none> arn:aws:iam::632128666759:role/study_wildcard-20250322164755327400000010 subnet-0fb7743ba258e0484,subnet-0e566d9ba1cf69706,subnet-07cd710d1aecc83c5 Blueprint=fargate-serverless,GithubRepo=github.com/aws-ia/terraform-aws-eks-blueprints ACTIVE
## rbac 확인
k rbac-tool llokup system:node-proxier
## rolesum 확인
k rolesum -k Group system:node-proxier
## cni 확인
k get cm -n kube-system amazon-vpc-cni -o yaml
## coredns
k get cm -n kube-system coredns -o yaml
## 인증서 확인
k get cm -n kube-system extension-apiserver-authentication -o yaml
## kube-proxy 확인
k get cm -n kube-system kube-proxy -o yaml
k get cm -n kube-system kube-proxy-config -o yaml
- coredns 파드 상세 정보 확인 : schedulerName: fargate-scheduler
- kube-ops-view 설치
# helm 배포
helm repo add geek-cookbook https://geek-cookbook.github.io/charts/
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set env.TZ="Asia/Seoul" --namespace kube-system
# 포트 포워딩
kubectl port-forward deployment/kube-ops-view -n kube-system 8080:8080 &
# 접속
open "http://127.0.0.1:8080/#scale=1.5"
- kube-ops-view 파드 정보 확인
## node 확인
k get csr
k get node -owide
k describe node | grep eks.amazonaws.com/compute-type
## kube-ops-view deploy / pod 정보 확인
k get pod -n kube-system
k get pod -n kube-system -o jsonpath='{.items[0].metadata.annotations.CapacityProvisioned}'
k get pod -n kube-system -l app.kubernetes.io/instance=kube-ops-view -o jsonpath='{.items[0].metadata.annotations.CapacityProvisioned}'
## deploy 상세 정보
k get deploy -n kube-system kube-ops-view -o yaml
## deploy 스케줄 확인
k get deploy -n kube-system kube-ops-view -o yaml
...
enableServiceLinks: true
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: kube-ops-view
...
## 파드 상세 정보 : admission control 확인
...
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: fargate-ip-10-10-27-74.ap-northeast-2.compute.internal
preemptionPolicy: PreemptLowerPriority
priority: 2000001000
priorityClassName: system-node-critical
restartPolicy: Always
schedulerName: fargate-scheduler
...
- netshoot 배포
## ns 생성
k create ns study-aews
## netshoot deploy 생성
## 0.5vCPU 1GB 할당되어, 아래 Limit 값은 의미가 없음. 배포 시 대략 시간 측정해보자!
cat <<EOF | k apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: netshoot
namespace: study-aews
spec:
replicas: 1
selector:
matchLabels:
app: netshoot
template:
metadata:
labels:
app: netshoot
spec:
containers:
- name: netshoot
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
resources:
requests:
cpu: 500m
memory: 500Mi
limits:
cpu: 2
memory: 2Gi
terminationGracePeriodSeconds: 0
EOF
##배포 시간 확인
k get events -w --sort-by '.lastTimestamp'## 메모리 할당 확인
k get pod -n study-aews -o jsonpath='{.items[0].metadata.annotations.CapacityProvisioned}' git:main*
## deploy 정보 확인
k get pod -n study-aews -o yaml## 파드 내부에서 추가 확인
k exec -it deploy-netshoot -n study-aews -- zsh
$ ip -c a
$ cat /etc/resolv.conf
$ curl ipinfo.io/ip
$ ping -c 1
$ lsblk
$ df -hT
$ cat /etc/fstab
exit
파드 권한과 호스트 네임스페이스 공유로 호스트 탈취 시도
## test pod 배포
k apply -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: root-shell
namespace: study-aews
spec:
containers:
- command:
- /bin/cat
image: alpine:3
name: root-shell
securityContext:
privileged: true
tty: true
stdin: true
volumeMounts:
- mountPath: /host
name: hostroot
hostNetwork: true
hostPID: true
hostIPC: true
tolerations:
- effect: NoSchedule
operator: Exists
- effect: NoExecute
operator: Exists
volumes:
- hostPath:
path: /
name: hostroot
EOF
## 파드 정보 확인
k get pod -n study-aews root-shell
k describe pod -n study-aews root-shell | grep Events: -A 10
## 삭제
k delete pod -n study-aews root-shell
생성 시 pod가 pending 상태에서 멈춰있는 것을 확인할 수 있으며, 이벤트 확인 시 fargate의 pod에서는 host 정보를 확인할 수 있는 것을 지우너하지 않고 보안 측면에서 권한 문제가 발생하는 것을 확인할 수 있다
Fargate ALB
- game2048을 deploy, svc, ingress 오브젝트를 사용하여 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: study-aews
name: deployment-2048
spec:
selector:
matchLabels:
app.kubernetes.io/name: app-2048
replicas: 2
template:
metadata:
labels:
app.kubernetes.io/name: app-2048
spec:
containers:
- image: public.ecr.aws/l6m2t8p7/docker-2048:latest
imagePullPolicy: Always
name: app-2048
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
namespace: study-aews
name: service-2048
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
type: ClusterIP
selector:
app.kubernetes.io/name: app-2048
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: study-aews
name: ingress-2048
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service-2048
port:
number: 80
EOF
Fargate Job
cat <<EOF | kubectl apply -f -
apiVersion: batch/v1
kind: Job
metadata:
name: busybox1
namespace: study-aews
spec:
template:
spec:
containers:
- name: busybox
image: busybox
command: ["/bin/sh", "-c", "sleep 10"]
restartPolicy: Never
ttlSecondsAfterFinished: 60 # <-- TTL controller
---
apiVersion: batch/v1
kind: Job
metadata:
name: busybox2
namespace: study-aews
spec:
template:
spec:
containers:
- name: busybox
image: busybox
command: ["/bin/sh", "-c", "sleep 10"]
restartPolicy: Never
EOF
예정 job에 잘 수행된 것을 확인할 수 있다.
Fargate logging
- fargate의 eks는 fluent bit 기반의 내장 로그 라우터를 제공, Sidecar pattern을 사용하지 않고 aws에서 직접 실행
- 로그 라우터를 사용하면 ㅁws의 다양한 서비스를 로그 분석 및 저장에 사용할 수 있음
- nginx 배포
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-app
namespace: study-aews
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:latest
name: nginx
ports:
- containerPort: 80
name: http
resources:
requests:
cpu: 500m
memory: 500Mi
limits:
cpu: 2
memory: 2Gi
---
apiVersion: v1
kind: Service
metadata:
name: sample-app
namespace: study-aews
spec:
selector:
app: nginx
ports:
- port: 80
targetPort: 80
protocol: TCP
type: ClusterIP
EOF
- 반복 접근 시 로그가 정상적으로 쌓이고 있는 것을 확인할 수 있음
로그가 설정되는 이유는 클러스터를 배포할 때 테라폼 코드에 enable_fargate_fluentbit = true 설정되어 있기 때문이다.
- 클러스터에서도 로그 확인
EKS Auto mode
EKS Automode는 EKSdㅔ서 자동으로 클러스터를 운영할 수 있도록 지원하는 모드입니다.
- 노드를 직접 관리하고 싶지 않을 때
- 단순 앱이나 테스트 환경 구성
- DaemonSet, GPU 등이 필요 없는 워크로드
- 보안, 격리성이 중요한 환경 (파드 단위 격리)
## Terraform 코드 clone
git clone https://github.com/aws-samples/sample-aws-eks-auto-mode.git
cd sample-aws-eks-auto-mode/terraform
## 변수 수정
region : us-east > ap-northeast-2
vpc cidr : 10.0.0.0/16 > 10.20.0.0/16
## Terraform 배포
terraform init
terraform plan
terraform apply -auto-approve
- node 관련 정보 확인
- nodeclass 확인
- nodepool 확인
- kube-ops-view 설치
## 모니터링
eks-node-viewer --node-sort=eks-node-viewer/node-cpu-usage=dsc --extra-labels eks-node-viewer/node-age
watch -d kubectl get node,pod -A
## 설치 확인
helm install kube-ops-view geek-cookbook/kube-ops-view --version 1.2.2 --set env.TZ="Asia/Seoul" --namespace kube-system
k get events -w --sort-by '.lastTimestamp'
k get nodeclaims
Karpenter 동작 확인
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate
spec:
replicas: 1
selector:
matchLabels:
app: inflate
template:
metadata:
labels:
app: inflate
spec:
terminationGracePeriodSeconds: 0
nodeSelector:
eks.amazonaws.com/compute-type: auto
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- name: inflate
image: public.ecr.aws/eks-distro/kubernetes/pause:3.7
resources:
requests:
cpu: 1
securityContext:
allowPrivilegeEscalation: false
EOF
- 파드 생성 후 replicas로 scale out 동작 테스트
#
kubectl scale deployment inflate --replicas 100 && kubectl get events -w --sort-by '.lastTimestamp'
#
kubectl scale deployment inflate --replicas 200 && kubectl get events -w --sort-by '.lastTimestamp'
#
kubectl scale deployment inflate --replicas 50 && kubectl get events -w --sort-by '.lastTimestamp'
파드가 모두 노드로 스케줄링되지 못하고 karpenter가 바로 동작해 node 생성이 트리거된 것을 확인할 수 있다.
노드가 생성되고 클러스터에 조인되면 pending 상태에 있던 pod들이 node에 스케줄링 되기 시작한다.
오른쪽의 기존 노드를 보면 빨간색으로 X 표시가 되고 있는 것을 확인할 수 있다.
신규 노드가 트리거되어 생성되고 pod 스케줄링이 완료되면 이전 파드가 삭제되는 것을 확인할 수 있다.
200개로 pod를 늘렸을 때에 이전과 동일하게 신규 노드가 생성되고 pending pod를 스케줄링하는 것을 확인할 수 있습니다.
단, 다른 점은 이전 노드를 삭제하고 1개 노드에 200개 파드를 스케줄링하는 것이 아니라, 2개 노드에 분산 배치하는 것을 확인할 수 있습니다.
50개로 줄였을 때 Old 노드의 pod를 모두 삭제하고 old node가 삭제되는 것을 확인하였습니다.
'Cloud > AWS' 카테고리의 다른 글
| [EKS] Blue-Green Migration (0) | 2025.04.06 |
|---|---|
| [AWS] EKS Security (0) | 2025.03.13 |
| [AWS] EKS Autoscaler - Karpenter (0) | 2025.03.09 |
| [AWS] EKS Autoscaler - CPA (0) | 2025.03.09 |
| [AWS] EKS Autoscaler - CAS (0) | 2025.03.09 |