
사전 환경 구성
이전과 동일하게 실습을 위한 클러스터는 kind를 이용해 배포합니다.
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
featureGates:
"InPlacePodVerticalScaling": true #실행 중인 파드의 리소스 요청 및 제한을 변경할 수 있게 합니다.
"MultiCIDRServiceAllocator": true #서비스에 대해 여러 CIDR 블록을 사용할 수 있게 합니다.
nodes:
- role: control-plane
labels:
mynode: control-plane
topology.kubernetes.io/zone: ap-northeast-2a
extraPortMappings: #컨테이너 포트를 호스트 포트에 매핑하여 클러스터 외부에서 서비스에 접근할 수 있도록 합니다.
- containerPort: 30000
hostPort: 30000
- containerPort: 30001
hostPort: 30001
- containerPort: 30002
hostPort: 30002
- containerPort: 30003
hostPort: 30003
- containerPort: 30004
hostPort: 30004
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
apiServer:
extraArgs: #API 서버에 추가 인수를 제공
runtime-config: api/all=true #모든 API 버전을 활성화
controllerManager:
extraArgs:
bind-address: 0.0.0.0
etcd:
local:
extraArgs:
listen-metrics-urls: http://0.0.0.0:2381
scheduler:
extraArgs:
bind-address: 0.0.0.0
- |
kind: KubeProxyConfiguration
metricsBindAddress: 0.0.0.0
- role: worker
labels:
mynode: worker1
topology.kubernetes.io/zone: ap-northeast-2a
- role: worker
labels:
mynode: worker2
topology.kubernetes.io/zone: ap-northeast-2b
- role: worker
labels:
mynode: worker3
topology.kubernetes.io/zone: ap-northeast-2c
networking:
podSubnet: 10.10.0.0/16 #파드 IP를 위한 CIDR 범위를 정의합니다. 파드는 이 범위에서 IP를 할당받습니다.
serviceSubnet: 10.200.1.0/24 #서비스 IP를 위한 CIDR 범위를 정의합니다. 서비스는 이 범위에서 IP를 할당받습니다.
- Cluster 배포
$ kind create cluster --config kind-svc.yaml --image kindest/node:v1.31.0
- Docker 명령어를 통해 배포 확인

- Docker 명령어를 통해 master, worker node에 필요한 패키지를 설치합니다.
$ docker exec -it myk8s-control-plane sh -c 'apt update && apt install tree psmisc lsof wget bsdmainutils bridge-utils net-tools dnsutils ipset ipvsadm nfacct tcpdump ngrep iputils-ping arping git vim arp-scan -y'
$ for i in worker worker2 worker3; do echo ">> node myk8s-$i <<"; docker exec -it myk8s-$i sh -c 'apt update && apt install tree psmisc lsof wget bsdmainutils bridge-utils net-tools dnsutils ipset ipvsadm nfacct tcpdump ngrep iputils-ping arping -y'; echo; done
- 생성된 클러스터 정보 확인
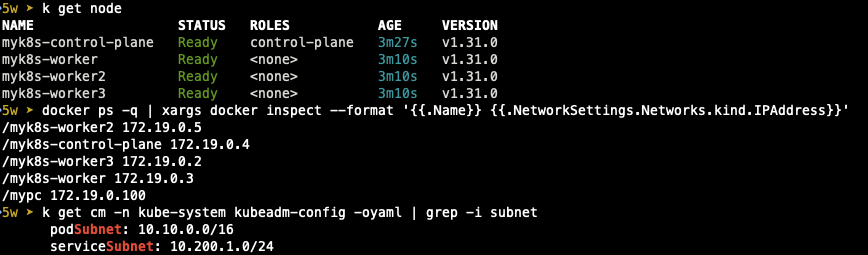
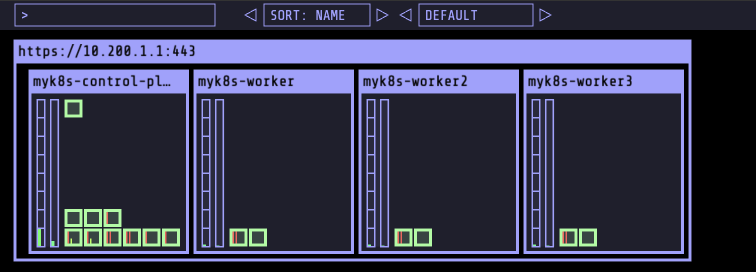
- helm을 이용해 kube-ops-view도 설치합니다.
전체적인 모니터링을 하기 위해 배치 노드를 Control-Plane으로 변경합니다.
- helm을 이용해 Grafana, prometheus까지 배포합니다.
Dashboadr는 metalLB를 Import하였습니다.
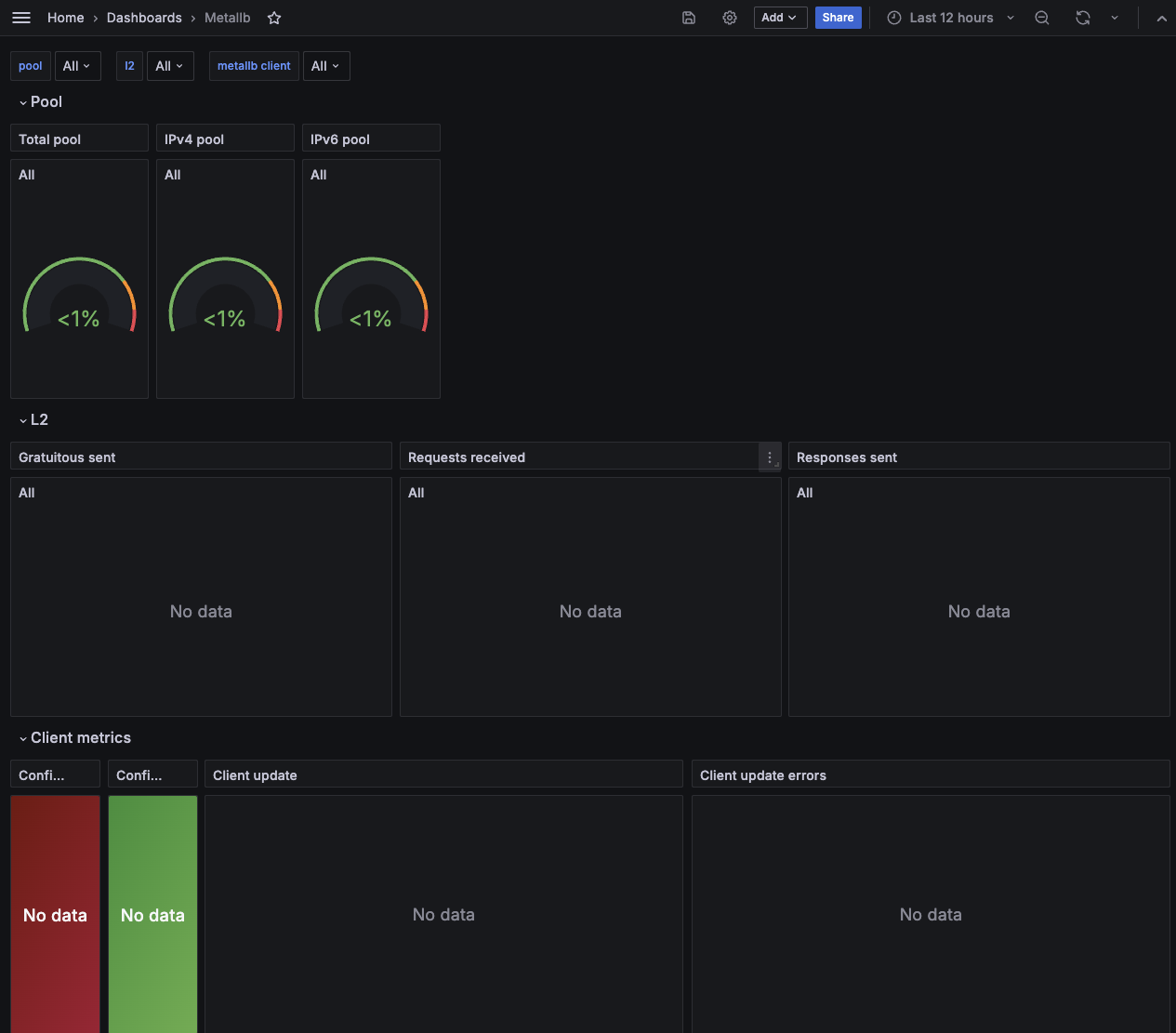
이로써 테스트를 위한 사전 환경 구성은 완성이 되었습니다.
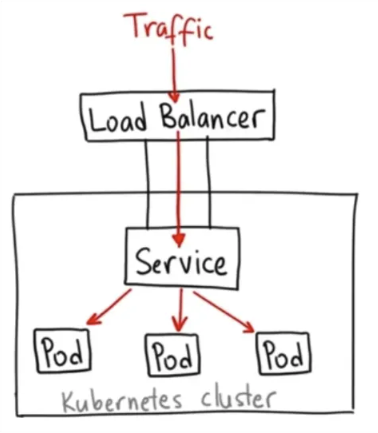
LoadBalancer
- CSP의 로드밸런서를 이용해 service를 외부로 노출 (on-prem에서 쓸 수 있는 metal LB도 있음)
- 외부 LB를 사용하기 때문에 SPOF에 강함
- L4(TCP), L7(HTTP) 레이어를 통해 service 노출
- LB의 포트를 80, 443으로 구성할 수 있기 때문에 프론트엔드에서 사용하기에 용이하고 HA 구성 운영에서도 유용하게 사용된다.
(Network, Proxy LB도 있기 때문에 반드시 프론트엔드에만 적합한 것은 아닙니다.) - ingress를 연계해서 사용
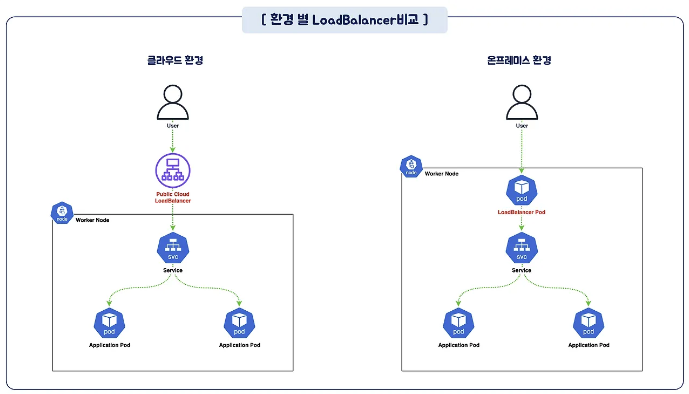
- AWS의 LoadBalancer
AWS는 기본적으로 3가지 종류의 LB를 지원합니다. (CLB(Classic LoadBalancer), NLB (Netowrk LoadBalancer), ALB (Application LoadBalancer))
CLB : NLB / ALB 에 비해 기능이 적고 AWS 초기에 주로 사용되던 LB입니다. Layer 4계층과 Layer 7계층을 모두 지원합니다.
NLB : Layer 4계층에서 동작하기 때문에 ALB에 비해 속도 처리가 빠르며, TCP, UDP, TLS 트래픽을 처리할 수 있습니다.
ALB : LAyer 7계층에서 동작하고, HTTP, HTTPS, gRPC 트래픽을 처리합니다. (WEB 어플리케이션 서빙에 가장 많이 사용됩니다.)
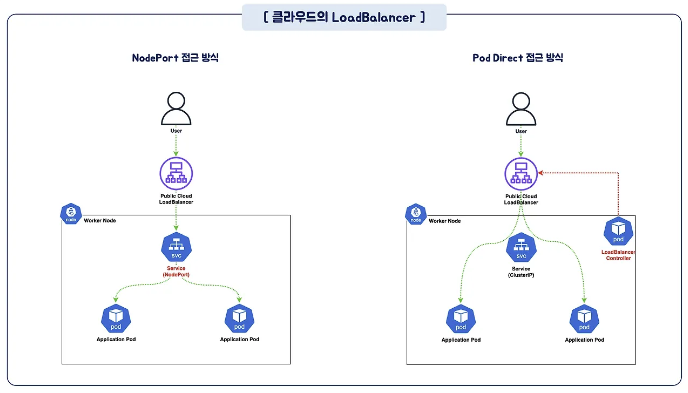
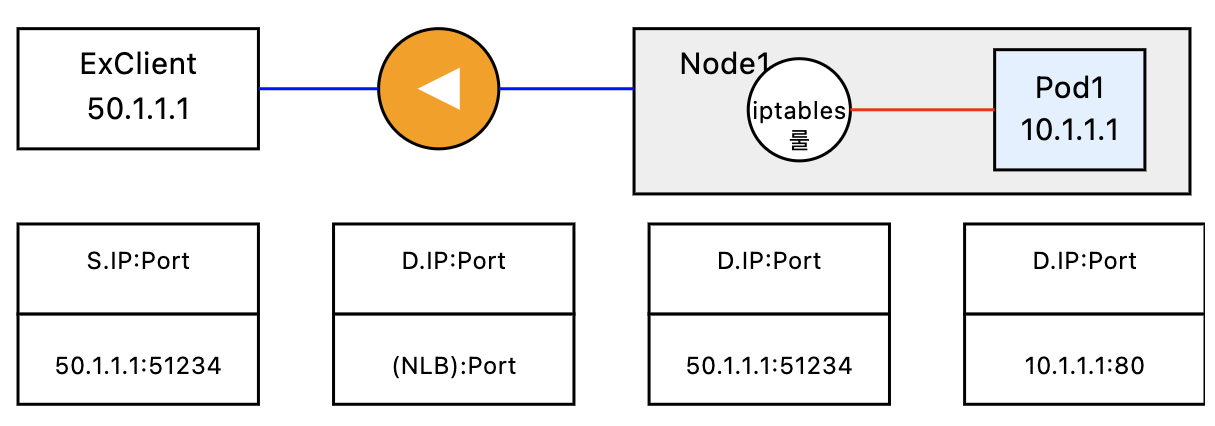
일반적으로 클라우드 로드밸런서의 분배 방신은 아래와 같이 Service를 통해 설정된 각 노드들로 트래픽을 전달하여 부하분산을 수행하지만, 서비스를 거치지 않고, AWS CNI와LoadBalancer Controler를 통해 파드의 IP로 직접 전달하는 방법도 있습니다.
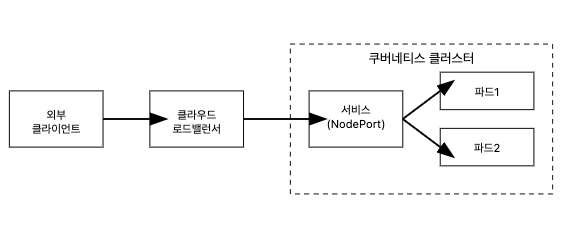
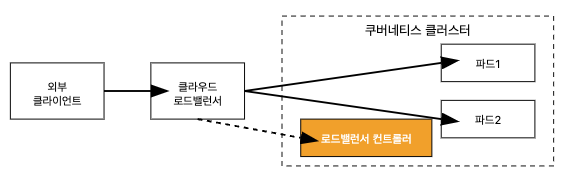
이 경우 노드는 외부에 공개되지 않고, 로드밸런서만 외부에 공개되어 외부 클라이언트는 로드밸런서에 접속을 할 뿐 내부 노드의 정보를 알 수 없습니다.
클라이언트가 POD로 접근 시 DNAT가 2번 발생합니다. 첫번째는 로드밸런서 접속 후 node로 나갈 때 도번째는 노드에서 iptables 정책을 통해 pod로 전달될 때 입니다.
MetalLB
MetalLB는 온프레미스 환경에서 사용할 수 있는 서비스이고, BareMetalLoadBalancer의 약자입니다.
동작 모드는 Layer2 모드 : ARP / NDP를 사용하여 로드밸런서 IP를 광고(advertise)합니다.
BGP 모드 : BGP 프로토콜을 사용하여 로드밸런서 IP를 네트워크에 광고(advertise)합니다.
실습 시작
- 파드 생성 (실습을 위해 worker1, worker2에만 배포)
apiVersion: v1
kind: Pod
metadata:
name: webpod1
labels:
app: webpod
spec:
nodeName: myk8s-worker
containers:
- name: container
image: traefik/whoami
terminationGracePeriodSeconds: 0
---
apiVersion: v1
kind: Pod
metadata:
name: webpod2
labels:
app: webpod
spec:
nodeName: myk8s-worker2
containers:
- name: container
image: traefik/whoami
terminationGracePeriodSeconds: 0
- 파드 IP 변수 지정
# 파드 IP주소를 변수에 지정
$ WPOD1=$(kubectl get pod webpod1 -o jsonpath="{.status.podIP}")
$ WPOD2=$(kubectl get pod webpod2 -o jsonpath="{.status.podIP}")
$ echo $WPOD1 $WPOD2
MetalLB 설치
$ kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/refs/heads/main/config/manifests/metallb-native-prometheus.yaml
- 배포 확인
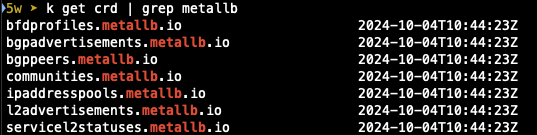
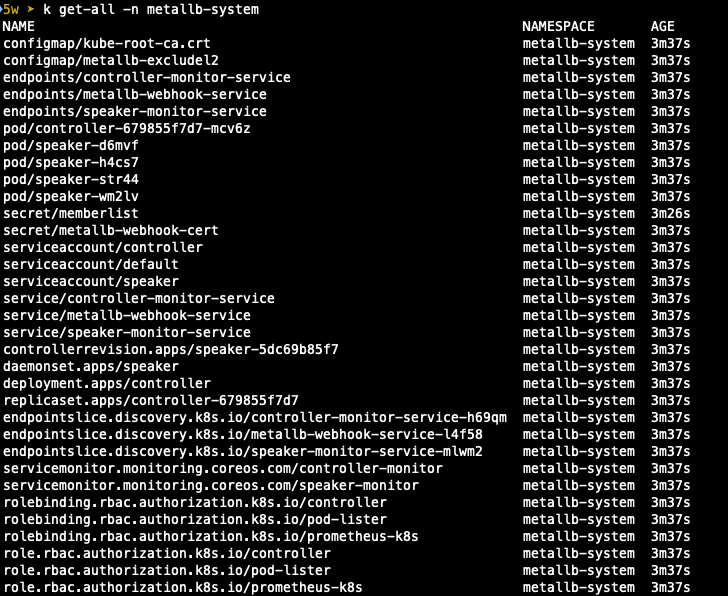
speaker pod는 host 네트워크를 그대로 사용하는 것도 확인할 수 있습니다.

아래 명령어를 통해 확인해보면 172.19.0.0 대역 중에 metallb에서 사용할 ip pool을 만들어서 사용할 수 있다는 설명이고,
그에 따라 ip pool을 만들어 보겠습니다.
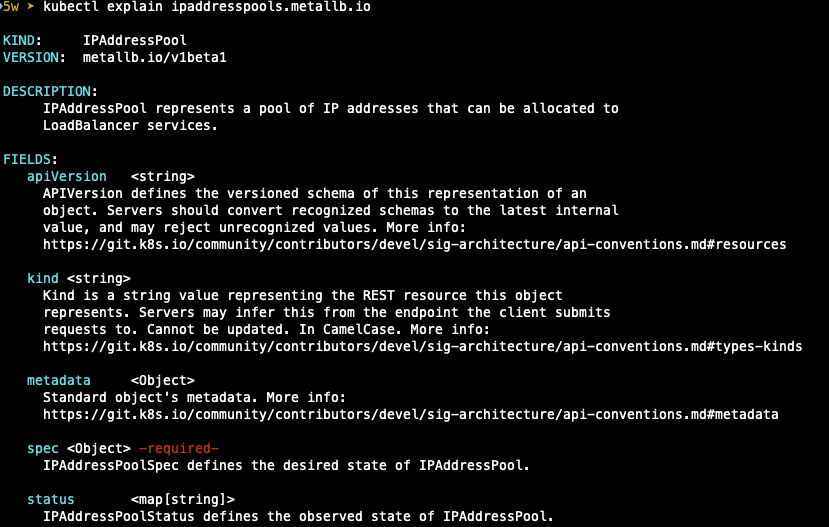
- IP Pool 생성
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: my-ippool
namespace: metallb-system
spec:
addresses:
- 172.18.255.200-172.18.255.250
배포하면 아래와 같이 metallb-system 네임 스페이스에 my-ippool이라는 이름의 ip pool이 생성된 것을 확인할 수 있습니다.

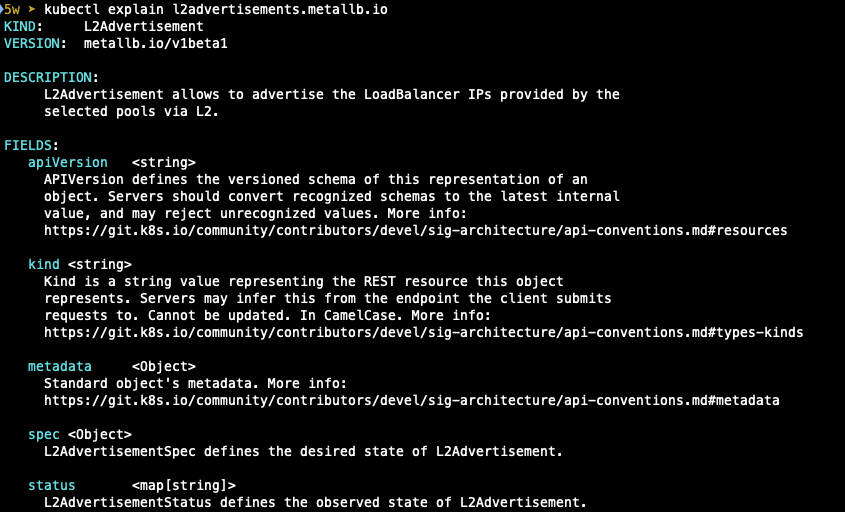
- L2advertisements에 대한 설명
L2Advertisement 생성 : 설정한 IPpool을 기반으로 Layer2 모드로 LoadBalancer IP 사용 허용합니다.
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: my-l2-advertise
namespace: metallb-system
spec:
ipAddressPools:
- my-ippool
- Log 설정하고, 서비스 생성하기
## Log 모니터링 설정
$ k krew install stern
$ k stern -n metallb-system speaker
## ARP Scan
$ docker exec -it myk8s-control-plane arp-scan --interfac=eth0 --localnet
## 서비스 생성
apiVersion: v1
kind: Service
metadata:
name: svc1
spec:
ports:
- name: svc1-webport
port: 80
targetPort: 80
selector:
app: webpod
type: LoadBalancer # 서비스 타입이 LoadBalancer
---
apiVersion: v1
kind: Service
metadata:
name: svc2
spec:
ports:
- name: svc2-webport
port: 80
targetPort: 80
selector:
app: webpod
type: LoadBalancer
---
apiVersion: v1
kind: Service
metadata:
name: svc3
spec:
ports:
- name: svc3-webport
port: 80
targetPort: 80
selector:
app: webpod
type: LoadBalancer
서비스를 확인하면 Type이 LoadBalancer로 설정되어 생성되었고,
모니터링하고 있던 speaker pod 쪽에서도 로그가 캡쳐되는 것을 확인할 수 있습니다.
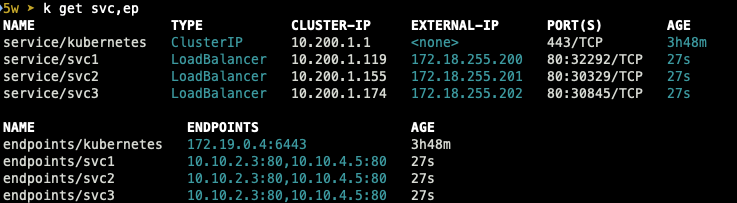
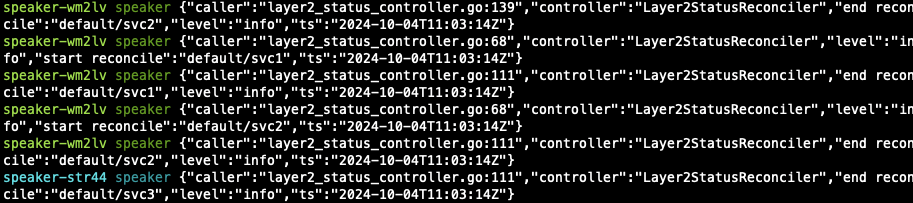
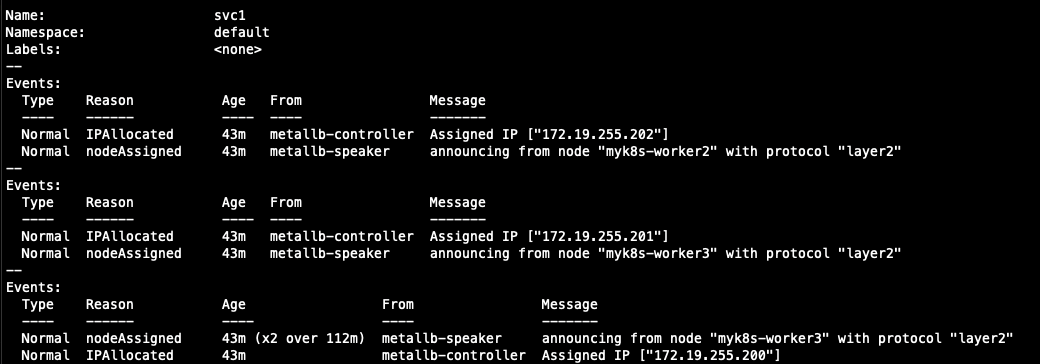
$ k describe svc/svc1
Name: svc1 # 서비스 명
Namespace: default # 네임스페이스 위치
Labels: <none>
Annotations: metallb.io/ip-allocated-from-pool: my-ippool ## Metallb의 IP를 my-IPPool로 부터 할당
Selector: app=webpod ## Selector 동작 기준
Type: LoadBalancer ## 서비스 타입
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.200.1.119 ## 서비스의 Cluster IP
IPs: 10.200.1.119
LoadBalancer Ingress: 172.18.255.200 ## 외부에서 접근가능한 External IP
Port: svc1-webport 80/TCP ## 서비스가 트래픽을 전달받을 포트
TargetPort: 80/TCP ## 서비스가 전달할 POD의 포트
NodePort: svc1-webport 32292/TCP ## 노드를 통해 접근할 Port
Endpoints: 10.10.2.3:80,10.10.4.5:80
Session Affinity: None ## 서비스에서 pod로 트래픽을 흘려주는 대상이 1개 파드가 아님을 정의하는 설정
External Traffic Policy: Cluster
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal IPAllocated 4m55s metallb-controller Assigned IP ["172.18.255.200"]
## External IP의 리더를 announce
Normal nodeAssigned 4m55s metallb-speaker announcing from node "myk8s-worker" with protocol "layer2"
Metalb의 serviceL2status도 조회해보겠습니다.
serviceL2status는 MetalLB의 Layer2 모드에서 운영과 관련한 상태 정보를 나타내며,
주로 문제 발생 시 정보를 확인하기 위해 사용하는 모니터링 도구로의 역할도 합니다.
$ kubectl describe servicel2status -n metallb-system
Name: l2-2bg77
Namespace: metallb-system
Labels: metallb.io/node=myk8s-worker
metallb.io/service-name=svc1
metallb.io/service-namespace=default
Annotations: <none>
API Version: metallb.io/v1beta1
Kind: ServiceL2Status
Metadata:
Creation Timestamp: 2024-10-04T11:03:14Z
Generate Name: l2-
Generation: 1
Managed Fields:
API Version: metallb.io/v1beta1
Fields Type: FieldsV1
fieldsV1:
f:metadata:
f:generateName:
f:labels:
.:
f:metallb.io/node:
f:metallb.io/service-name:
f:metallb.io/service-namespace:
f:ownerReferences:
.:
k:{"uid":"7a273648-bb43-4f73-b722-9479d8f5d176"}:
f:spec:
Manager: speaker
Operation: Update
Time: 2024-10-04T11:03:14Z
API Version: metallb.io/v1beta1
Fields Type: FieldsV1
fieldsV1:
f:status:
.:
f:node:
f:serviceName:
f:serviceNamespace:
Manager: speaker
Operation: Update
Subresource: status
Time: 2024-10-04T11:03:14Z
Owner References:
API Version: v1
Kind: Pod
Name: speaker-wm2lv
UID: 7a273648-bb43-4f73-b722-9479d8f5d176
Resource Version: 23218
UID: 0850d0c5-869d-47aa-a60d-a97581d92ca5
Spec:
Status:
Node: myk8s-worker
Service Name: svc1
Service Namespace: default
Events: <none>
이전에 Docker에 배포한 mypc 컨테이너를 통해 arping을 통해서 reader speaker pod를 확인해 볼 수 있습니다.
$ for i in $SVC1EXIP $SVC2EXIP $SVC3EXIP; do docker exec -it mypc ping -c 1 -w 1 -W 1 $i; done
$ for i in 172.18.0.2 172.18.0.3 172.18.0.4 172.18.0.5; do docker exec -it mypc ping -c 1 -w 1 -W 1 $i; done
########################################################################
5w ➤ docker exec -it mypc ip -c neigh | sort
172.19.0.2 dev eth0 lladdr 02:42:ac:13:00:02 REACHABLE
172.19.0.3 dev eth0 lladdr 02:42:ac:13:00:03 REACHABLE
172.19.0.4 dev eth0 lladdr 02:42:ac:13:00:04 REACHABLE
172.19.0.5 dev eth0 lladdr 02:42:ac:13:00:05 REACHABLE
172.19.255.200 dev eth0 lladdr 02:42:ac:13:00:02 REACHABLE
172.19.255.201 dev eth0 lladdr 02:42:ac:13:00:02 REACHABLE
172.19.255.202 dev eth0 lladdr 02:42:ac:13:00:05 REACHABLE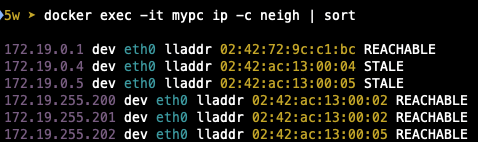

Service의 external IP 대역의 mac 주소를 보면 02:42:ac:13:00:02가 표시되고 node IP에서 찾으면
172.19.0.2(worker3) 의 맥과 동일한 것을 확인할 수 있습니다.
이를 통해 리더 speaker의 파드도 확인할 수 있습니다.
service의 Describe로 실제 announce된 내용과 동일한지 확인하여 검증해보면 worker3이 reader speaker pod인 것을 확인할 수 있습니다.
- LoadBalancer IP를 통해 외부에서 접근해보기
node의 IP가 아닌 Service External IP로 접속했을 때 정상적으로 접속되는 것을 확인할 수 있습니다.
클라이언트 → 서비스(External-IP) 접속 시 : 리더 파드가 존재하는 노드 인입 후 Service 에 매칭된 iptables rules 에 따라 랜덤 부하 분산되어서(SNAT) 파드로 접속되기 때문에 node ip가 아닌 external ip로 통신이 가능합니다.
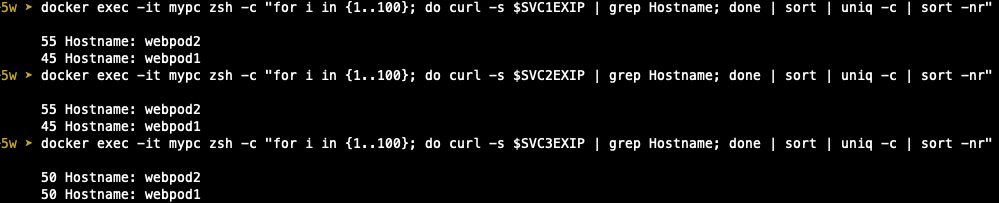
$ for i in $SVC1EXIP $SVC2EXIP $SVC3EXIP; do echo ">> Access Service External-IP : $i <<" ; docker exec -it mypc curl -s $i; echo ; done
>> Access Service External-IP : 172.19.255.202 <<
Hostname: webpod2
IP: 127.0.0.1
IP: ::1
IP: 10.10.4.5
IP: fe80::c01f:51ff:fe56:27d7
RemoteAddr: 10.10.4.1:10971
GET / HTTP/1.1
Host: 172.19.255.202
User-Agent: curl/8.7.1
Accept: */*
>> Access Service External-IP : 172.19.255.201 <<
Hostname: webpod1
IP: 127.0.0.1
IP: ::1
IP: 10.10.2.3
IP: fe80::547f:70ff:fe52:5ea9
RemoteAddr: 172.19.0.2:28756
GET / HTTP/1.1
Host: 172.19.255.201
User-Agent: curl/8.7.1
Accept: */*
>> Access Service External-IP : 172.19.255.200 <<
Hostname: webpod2
IP: 127.0.0.1
IP: ::1
IP: 10.10.4.5
IP: fe80::c01f:51ff:fe56:27d7
RemoteAddr: 172.19.0.2:1177
GET / HTTP/1.1
Host: 172.19.255.200
User-Agent: curl/8.7.1
Accept: */*
각 pod로 분산이 정상적으로 이뤄지고 있는지 uniq를 통해 빈도를 확인해 보았습니다.
Failover
Leader Speaker pod의 node 장애 발생 시 남아있는 Speaker Pod는 Leader node의 장애를 인식하고,
Leader pod를 다시 정합니다. 결정된 Leader pod는 GARP로 자신이 Leader가 되었음을 전파하게 됩니다.
Layer2 모드의 경우 노드 장애 또는 파드 장애 . 시10초 ~ 1분 가량의 장애 지속 시간이 소요됩니다. (서비스 복잡성에 따라 증가)
내부 프로세스상 장애 디스커버리 타임이 허용되지 않는다면 Layer2 모드 자체의 사용을 재검토하여야 합니다.
실습
- 사전 준비
## LB로 지속 접근할 수 있도록 loop 요청 수행
$ SVC1EXIP=$(kubectl get svc svc1 -o jsonpath='{.status.loadBalancer.ingress[0].ip}')
$ docker exec -it mypc zsh -c "while true; do curl -s --connect-timeout 1 $SVC1EXIP | egrep 'Hostname|RemoteAddr'; date '+%Y-%m-%d %H:%M:%S' ; echo ; sleep 1; done"## 상태 모니터링
$ watch -d kubectl get pod,svc,ep
## 로그 모니터링
$ kubectl stern -n metallb-system -l app=metallb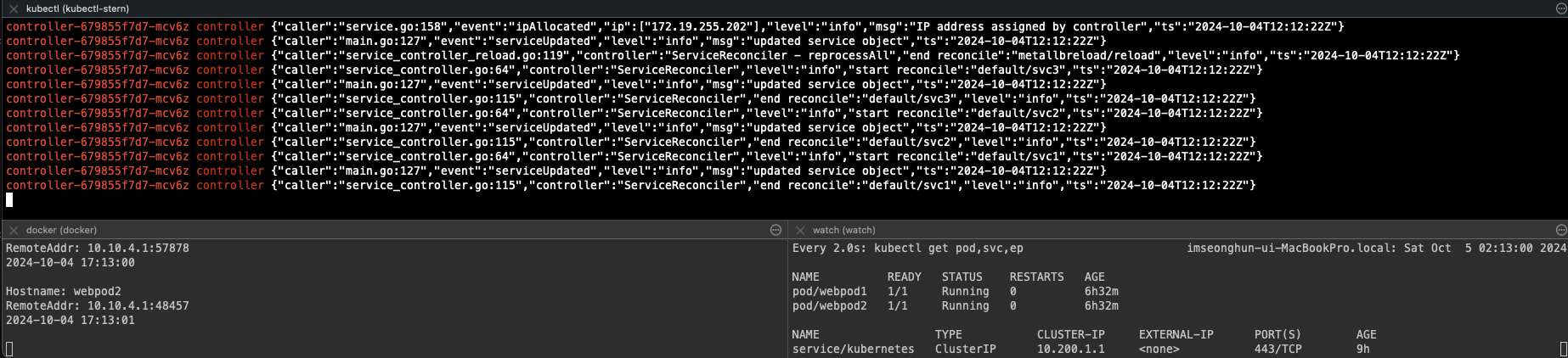
- 장애 재현
이전에 확인했던 내용에서 worker3이 leader인 것으로 확인되기 때문에 worker3을 중지하여 장애를 발생시켜보겠습니다.
$ docker stop myk8s-worker3 --signal 9
worker를 중지 시키면 로그 모니터링에서 여러 에러가 발생하고있고, curl 요청도 약간은? 잠깐? 불안했던 증상도 보였습니다.
간단하게 ping만 놓고 보았기 때문에 불안하고, ping loss 수준의 불안정한 통신 수준으로 보였습니다.

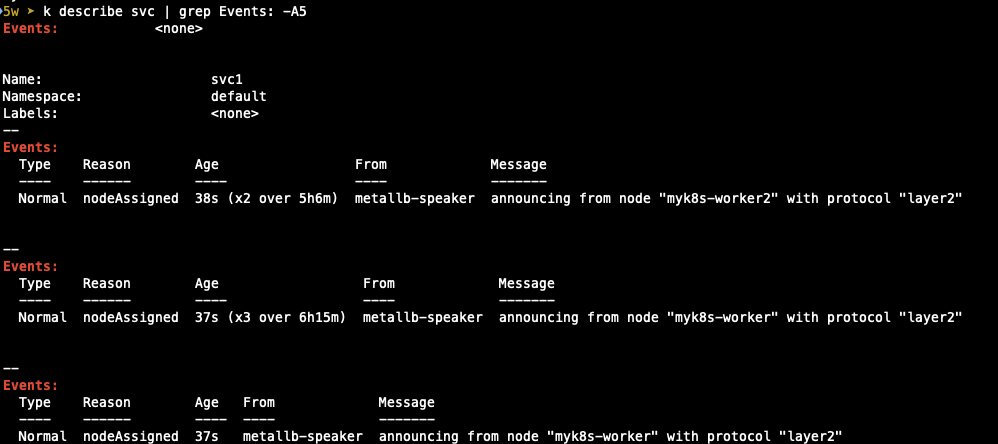
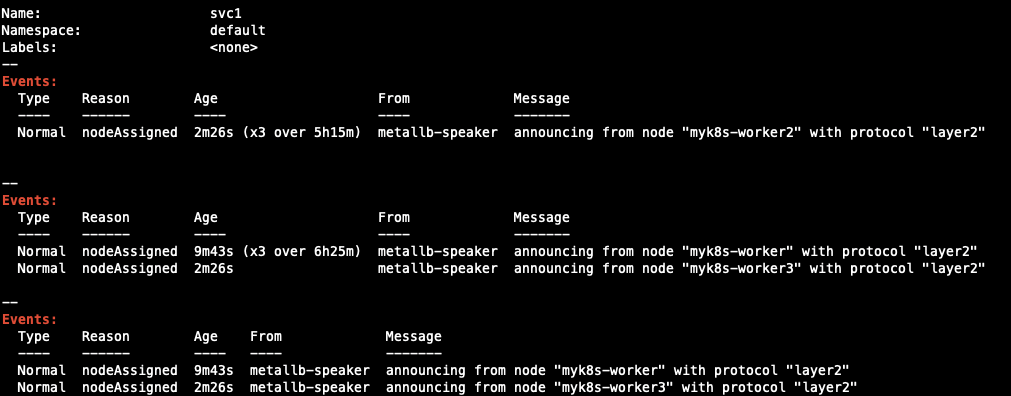
describe를 통해 event를 확인해보면 Leader를 다시 정해 배정된 것도 확인할 수 있습니다.
이 상태에서 중지한 node를 다시 기동하면 어떻게 될까요?
MetalLB에서 node가 다시 기동되어 클러스터에 조인된 것을 인지했다는 로그가 확인됩니다.

또, MetalLB에서 172.19.255.201에 발생했던 Announcement가 철회된 것을 확인할 수 있으므로 해당 서비스가 타 노드로 이전되었음을 예상할 수 있습니다.

worker node가 기동되고 장애가 해소되면 Failover에서 Failback이 이뤄졌는지 확인하기 위해 service를 describe해 확인했습니다.
worker3가 중지되면서 leader가 되었던 worker1에서 다시 기존의 worker3으로 leader pod가 변경된 것을 확인할 수 있었습니다.
'Cloud > Kubernetes' 카테고리의 다른 글
| [KANS] Gateway API (3) | 2024.10.13 |
|---|---|
| [KANS] Ingress (0) | 2024.10.13 |
| [KANS] Service : ClusterIP, NodePort (1) | 2024.09.28 |
| [KANS] Calico 네트워크 모드 (1) | 2024.09.15 |
| [KANS] Calico CNI 기본 통신 (0) | 2024.09.14 |