
실습 환경은 Kind를 이용해서 진행했습니다.
Service
- Pod 집합과 같은 어블리케이션에 접근 경로나 Service Discovery 제공
- Pod를 외부 네트워크에 연결하고, pod로의 연결을 로드밸런싱하는 네트워크 오브젝트
- 하나의 Microservice 단위
- 서비스이름.네임스페이스.svc.cluster.local 이라는 FQDN 생성
- 껍데기만 있는 추상적인 객체
Kubernetes의 Pod는 Lifecycle 혹은 어떤 이유에 따라 언제든 재시작이 발생할 수 있습니다.
Computing 측면에서는 이를 방지하기 위해 Deployment가 그룹으로 Pod를 정의된 숫자만큼 보장하고 있습니다.
그렇다면 Computing resource 측면에서 Deployment가 이를 보장해준다면 Networking 측면에서는 Service가 보장합니다.
앞서 이야기한 것과 같이 Pod는 언제든 재시작이 이뤄질 수 있습니다. Pod에 할당된 IP 역시 재생성이되면 바뀔 수 있습니다.
Pod의 IP로 서비스를 연결했다면 Pod가 다시 시작하는 순간 서비스의 장애가 발생할 것입니다.
Service는 configure 내에 설정된 Endpoint에 따라 Pod로 Traffic을 전달합니다.
이런 설정을 통해 아래와 같이 Pod가 종료되어도 Service는 새로운 Pod로 Traffic을 전달하기 때문에 서비스 연속성이 이어집니다.
물론 이 과정에서는 Graceful Shutdown과 같은 세부 설정은 필요하지만 Flow는 크게 다르지 않습니다.

Cluster IP
- K8S 클러스터 내부에서만 통신이 가능한 Internal network 가상 IP 할당
- service - pod 간 통신은 kube-proxy가 담당
- 서비스 디버깅이나 테스트 시 사용
- 백엔드 앱에서 많이 사용함

Kind 구성 파일
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
featureGates:
"InPlacePodVerticalScaling": true
"MultiCIDRServiceAllocator": true
nodes:
- role: control-plane
labels:
mynode: control-plane
extraPortMappings:
- containerPort: 30000
hostPort: 30000
- containerPort: 30001
hostPort: 30001
- containerPort: 30002
hostPort: 30002
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
apiServer:
extraArgs:
runtime-config: api/all=true
- role: worker
labels:
mynode: worker1
- role: worker
labels:
mynode: worker2
- role: worker
labels:
mynode: worker3
networking:
podSubnet: 10.10.0.0/16
serviceSubnet: 10.200.1.0/24## kind cluster 생성
$ kind create cluster --config kind-svc-1w.yaml --name myk8s --image kindest/node:v1.31.0
각 node와 control plan이 정상적으로 설치되었고, 사설 IP까지 wide 옵션을 통해 확인할 수 있습니다.


Cluster info 를 통해 service와 cluster 의 cidr을 확인해 볼 수도 있습니다.
$ kubectl cluster-info dump | grep -m 2 -E "cluster-cidr|service-cluster-ip-range"
생성된 내부 클러스터의 네트워크 정보를 확인해보겠습니다.
# kube-proxy configmap 확인
$ kubectl describe cm -n kube-system kube-proxy
...
mode: iptables
iptables:
localhostNodePorts: null
masqueradeAll: false
masqueradeBit: null
minSyncPeriod: 1s
syncPeriod: 0s
...
# 노드 별 네트워트 정보 확인 : CNI는 kindnet 사용
$ for i in control-plane worker worker2 worker3; do echo ">> node myk8s-$i <<"; docker exec -it myk8s-$i ls /opt/cni/bin/; echo; done
$for i in control-plane worker worker2 worker3; do echo ">> node myk8s-$i <<"; docker exec -it myk8s-$i cat /etc/cni/net.d/10-kindnet.conflist; echo; done
$ for i in control-plane worker worker2 worker3; do echo ">> node myk8s-$i <<"; docker exec -it myk8s-$i ip -c route; echo; done
$ for i in control-plane worker worker2 worker3; do echo ">> node myk8s-$i <<"; docker exec -it myk8s-$i ip -c addr; echo; done
$ for i in control-plane worker worker2 worker3; do echo ">> node myk8s-$i <<"; docker exec -it myk8s-$i ip -c -4 addr show dev eth0; echo; done
# iptables 정보 확인
$ for i in filter nat mangle raw ; do echo ">> IPTables Type : $i <<"; docker exec -it myk8s-control-plane iptables -t $i -S ; echo; done
$ for i in filter nat mangle raw ; do echo ">> IPTables Type : $i <<"; docker exec -it myk8s-worker iptables -t $i -S ; echo; done
$ for i in filter nat mangle raw ; do echo ">> IPTables Type : $i <<"; docker exec -it myk8s-worker2 iptables -t $i -S ; echo; done
$ for i in filter nat mangle raw ; do echo ">> IPTables Type : $i <<"; docker exec -it myk8s-worker3 iptables -t $i -S ; echo; done
위에서 언급한 내용과 같이 cni는 kindnet을 사용하였습니다.
kindnet은 bridge를 사용하지 않고, direct 방식인 것도 확인할 수 있습니다.


docker명령어를 통해 컨트롤 플레인에서 arp-scan을 통해 eth0의 arp 패킷 정보를 확인합니다.
$ docker exec -it myk8s-control-plane arp-scan --interfac=eth0 --localnet
클러스터에 조인되지 않은 별도 컨테이너를 생성하여, 노드에 통신이 가능한지 확인을 위해 컨테이너를 기동합니다.
## 별도의 네트워크를 사용하면 --ip 옵션을 통해 ip 고정이 가능합니다.
$ docker run -d --rm --name mypc --network kind --ip 172.19.0.100 nicolaka/netshoot sleep infinity
mypc에서 Cluster로 통신 테스트가 가능한지 확인해 봅니다.
$ docker exec -it mypc ping -c 1 172.18.0.1
$ for i in {1..5} ; do docker exec -it mypc ping -c 1 172.18.0.$i; done
Cluster IP 실습
- 목적지(Backend) Pod 생성
apiVersion: v1
kind: Pod
metadata:
name: webpod1
labels:
app: webpod
spec:
nodeName: myk8s-worker
containers:
- name: container
image: traefik/whoami
terminationGracePeriodSeconds: 0
---
apiVersion: v1
kind: Pod
metadata:
name: webpod2
labels:
app: webpod
spec:
nodeName: myk8s-worker2
containers:
- name: container
image: traefik/whoami
terminationGracePeriodSeconds: 0
---
apiVersion: v1
kind: Pod
metadata:
name: webpod3
labels:
app: webpod
spec:
nodeName: myk8s-worker3
containers:
- name: container
image: traefik/whoami
terminationGracePeriodSeconds: 0
- Clent(Test Pod) 생성
apiVersion: v1
kind: Pod
metadata:
name: net-pod
spec:
nodeName: myk8s-control-plane
containers:
- name: netshoot-pod
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
- Service 생성
apiVersion: v1
kind: Service
metadata:
name: svc-clusterip
spec:
ports:
- name: svc-webport
port: 9000 # 서비스 IP 에 접속 시 사용하는 포트 port 를 의미
targetPort: 80 # 타킷 targetPort 는 서비스를 통해서 목적지 파드로 접속 시 해당 파드로 접속하는 포트를 의미
selector:
app: webpod # 셀렉터 아래 app:webpod 레이블이 설정되어 있는 파드들은 해당 서비스에 연동됨
type: ClusterIP # 서비스 타입
- 생성 확인

- TestPod 에서 webpod1~3으로 접속 테스트
## webpod 변수 설정
$ WEBPOD1=${kubectl get pod webpod1 -o jsonpath={.status.podIP}
$ WEBPOD2=${kubectl get pod webpod2 -o jsonpath={.status.podIP}
$ WEBPOD3=${kubectl get pod webpod3 -o jsonpath={.status.podIP}
## Curl로 접속 테스트
$ for pod in $WEBPOD1 $WEBPOD2 $WEBPOD3; do kubectl exec -it net-pod -- curl -s $pod; done
$ for pod in $WEBPOD1 $WEBPOD2 $WEBPOD3; do kubectl exec -it net-pod -- curl -s $pod | grep Hostname; done
$ for pod in $WEBPOD1 $WEBPOD2 $WEBPOD3; do kubectl exec -it net-pod -- curl -s $pod | grep Host; done
$ for pod in $WEBPOD1 $WEBPOD2 $WEBPOD3; do kubectl exec -it net-pod -- curl -s $pod | egrep 'Host|RemoteAddr'; done
- 서비스 IP 변수 지정
$ SVC1=$(kubectl get svc svc-clusterip -o jsonpath={.spec.clusterIP})
- Control plane iptables 정책 확인
정책을 확인해보면 control plan은 워커노드의 Service로 통신이 가능하도록 설정된 정책을 확인할 수 있습니다.
이 정책은 Kube-Proxy에 의해 생성된 룰셋입니다.



Cluster IP는 위 그림에 작성된 것과 같이 분산룰이 적용되어 있습니다.
실제로 Service에서 하단의 Pod로 분산을 시켜줍니다. 분산이 있는지 이어서 확인해 보겠습니다.
변수로 설정한 Service IP로 100번의 Curl 요청해 결과 값에서 Hostname을 뽑아 Hostname 별 횟수를 확인해보면
아래와 같이 분산되고 있는 것을 확인할 수 있습니다.
$ kubectl exec -it net-pod -- zsh -c "for i in {1..100}; do curl -s $SVC1:9000 | grep Hostname; done | sort | uniq -c | sort -nr"
Control plane 에서 분산 룰을 통해 변경되어 전달되는테이블을 conntrack 으로 확인할 수 있습니다.
## Control Plane 에서 확인
$ conntrack -E ## 전체 이벤트 내역 확인
$ conntrack -C ## 이벤트 갯수 카운트
$ conntrack -S ## 전체 통계
각 worker node에 접속해 tcpdump를 확인해보겠습니다.
통신은 test pod에서 worker node 1번으로 서비스 포트 9000으로 통신 시도를 했습니다.
$ docker exec -it myk8s-worker bash
$ docker exec -it myk8s-worker2 bash
$ docker exec -it myk8s-worker3 bash
$ kubectl exec -it net-pod -- zsh -c "for i in {1..100}; do curl -s $SVC1:9000 | grep Hostname; sleep 1; done"
IPTABLES 정책
Prerouting 확인을 위해 Control plane 에서 아래 명령어를 수행합니다.
$ iptables -v --numeric --table nat --list PREROUTING | column -t
정책을 확인하면 Docker 관련 네트워크가 아니면 Kube-service로 넘겨주는 것을 확인할 수 있습니다.

Kube-service의 정책을 한번 확인해보면 목적지가 Cluster IP에 9000번 포트는 Target으로 보내주는 정책을 확인할 수 있습니다.
$ iptables -v --numeric --table nat --list KUBE-SERVICES | column
그렇다면 Target의 정체를 확인하기 위해 Target의 정책을 확인해 보겠습니다.
정책을 확인해보면 들어온 요청을 각각의 파드로 전달해주는 것을 확인할 수 있습니다.
$ iptables -v --numeric --table nat --list KUBE-SVC-KBDEBIL6IU6WL7RF
Pod 죽이고 서비스 확인해보기
처음 서비스에 대해 이야기할 때 하나의 pod가 죽어도 deployment에 의해 개수가 보장되고,
신규로 생성되는 pod에 대한 네트워크는 service에서 연속성을 갖고 간다고 이야기했습니다.
이게 실제로 이야기한 내용과 같이 실행되는지 확인해 보겠습니다.
- 기존 환경 확인
## 터미널 1번
$ watch -d 'kubectl get pod -owide;echo; kubectl get svc,ep svc-clusterip;echo; kubectl get endpointslices -l kubernetes.io/service-name=svc-clusterip'
## 터미널 2번
$ SVC1=$(kubectl get svc svc-clusterip -o jsonpath={.spec.clusterIP})
$ kubectl exec -it net-pod -- zsh -c "while true; do curl -s --connect-timeout 1 $SVC1:9000 | egrep 'Hostname|IP: 10'; date '+%Y-%m-%d %H:%M:%S' ; echo ; sleep 1; done"
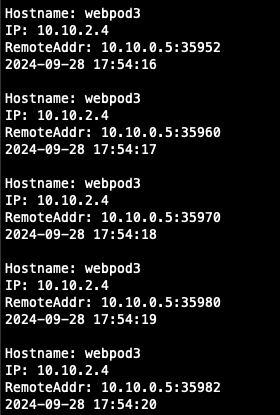
현재 webpod3의 ip는 10.10.2.3입니다. 이 상태에서 webpod3을 삭제하면 어떻게 되는지 확인해 보겠습니다.
$ kubectl delete pod webpod3
Pod3이 다시 실행되고 기존과 달리 pod의 IP가 달라졌지만 Service와 Endpoind에서 생성된 pod의 신규 ip를 잘 가지고 왔고,
curl 통신도 정상적으로 되는 것을 확인할 수 있습니다.
(물론 pod 생성 시 오류가 발생하면 service와 endpoint에도 연결되지 않습니다.)

sessionAffinity: ClientIP
sessionAffinity: ClientIP는 Sticky Session과 같이 클라이언트가 접속한 목적지를 고정하는 설정입니다. K8s_docs
- Default 설정 확인

- 접속 test loop
$ kubectl exec -it net-pod -- zsh -c "while true; do curl -s --connect-timeout 1 $SVC1:9000 | egrep 'Hostname|IP: 10|Remote'; date '+%Y-%m-%d %H:%M:%S' ; echo ; sleep 1; done"
- Patch 명령어를 통해 설정 활성화
$ kubectl patch svc svc-clusterip -p '{"spec":{"sessionAffinity":"ClientIP"}}'
- 접속 시도 내역 확인
- IPTABLES 정책 확인
정책 확인 시 recent --rcheck 10800으로 설정되어 있는 것을 확인할 수 있습니다.
recent는 동적으로 IP 주소 목록을 생성하고 확인하고, rcheck는 현재 IP List에 IP가 있는지 체크합니다.
즉, 10800초 (30분) 동안 클라이언트 IP를 리스트로 관리하여 고정해 Endpoint로 접속하도록 forwoard해주는 것입니다.
$ iptables -t nat -S | grep recent
NodePort
- NAT를 이용해 클러스터 내 Node의 고정된 port를 갖는 IP로 service 노출
- 외부 트래픽을 서비스에 전달하는 가장 기본적인 방법
- 클러스터 외부에서 접근은: <nodeIP>:<nodePort>
- Port range : 30000-32767
- node port를 지정할 수 있지만 지정하지 않으면 range 내에서 random 할
- Client가 접근 시 포트를 붙여야 하는 불편함이 있어 일반적으로 사용하지 않고, API등 코드에서 Exact한 서비스에 주로 사용함

NodePort 실습
실습 환경 구성
- Deployment 생성
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-echo
spec:
replicas: 3
selector:
matchLabels:
app: deploy-websrv
template:
metadata:
labels:
app: deploy-websrv
spec:
terminationGracePeriodSeconds: 0
containers:
- name: kans-websrv
image: mendhak/http-https-echo
ports:
- containerPort: 8080
- NodePort 용 Service 생성
apiVersion: v1
kind: Service
metadata:
name: svc-nodeport
spec:
ports:
- name: svc-webport
port: 9000 # 서비스 ClusterIP 에 접속 시 사용하는 포트 port 를 의미
targetPort: 8080 # 타킷 targetPort 는 서비스를 통해서 목적지 파드로 접속 시 해당 파드로 접속하는 포트를 의미
selector:
app: deploy-websrv
type: NodePort
- 생성 후 확인

- NodePort 확인 및 변수 설정
$ NPORT=$(kubectl get service svc-nodeport -o jsonpath='{.spec.ports[0].nodePort}')
$ echo $NPORT
- Node IP 변수 선언

- 접속 테스트
$ docker exec -it mypc curl -s $CNODE:$NPORT | jq
접근 로그를 보면 host header의 ip가 이상한 것을 볼 수 있습니다.
mypc의 컨테이너 사설 IP는 아래 그림과 같이 172.19.0.100 인데 실제 로그에 찍힌 것은 172.19.0.2로 다른 것이 확인됩니다.
명령어를 보면 curl 요청을 Control plane으로 수행한 것을 볼 수 있고, 172.19.0.2는 Control Plane의 IP라는 것도 위의 캡쳐에서 확인할 수 있습니다.

아래 그림을 확인해보면 Node Port로 service에 접근 시도를 할 경우 iptables rule에 의해 접속 시 Source NAT가 설정되는 것을 확인할 수 있고, 그로 인해 Host header에서 Control Plane의 IP가 보이는 것 입니다.

- IPTABLES 정책 확인
$ iptables -t nat -S | grep PREROUTING
$ iptables -t nat -S | grep KUBE-SERVICES
$ NPORT=$(kubectl get service svc-nodeport -o jsonpath='{.spec.ports[0].nodePort}')
$ iptables -t nat -S | grep KUBE-NODEPORTS | grep $NPORT
externalTrafficPolicy 설정
externalTrafficPolicy: Local : NodePort 로 접속 시 해당 노드에 배치된 파드로만 접속됨, 이때 SNAT 되지 않아서 외부 클라이언트 IP가 보존됩니다.
- Cluster Default 설정 확인

- node port svc 재생성

- externalTrafficPolicy 설정 변경
$ kubectl patch svc svc-nodeport -p '{"spec":{"externalTrafficPolicy": "Local"}}'
$ kubectl get svc svc-nodeport -o json | grep 'TrafficPolicy'
- Deploy Pod 개수 축소
$ kubectl scale deployment deploy-echo --replicas=2
- 접속 테스트
## Control Plane을 통한 접근 테스트
$ docker exec -it mypc curl -s --connect-timeout 1 $CNODE:$NPORT | jq
## 각 node별 접속 테스트
$ for i in $CNODE $NODE1 $NODE2 $NODE3 ; do echo ">> node $i <<"; docker exec -it mypc curl -s --connect-timeout 1 $i:$NPORT; echo; done
아래와 같이 Control Plane을 통한 접속은 불가능한 것을 확인할 수 있고, 각 node로 접속 시에도 실제 pod가 위치한 node로만 통신이 성공하는 것을 확인할 수 있습니다.
이전과 달리 Cluster와 각 Node에서 iptables 정책에 의해 pod로 트래픽을 전달하지 않고, externalTrafficPolicy Local 설정으로 인해 pod가 위치한 노드를 통해야만 접속이 가능합니다.


외부에서 노드의 IP와 포트로 직접 접속해야 한다는 것과 실제 통신 시 사설 IP가 외부에 공개되는 보안 문제가 발생할 수 있습니다.
Endpoint Slices
kube-proxy가 매번 모든 endpoint를 모니터링해야하고, 변경점이 발생했을 때 수시로 업데이트를 해줘야 합니다.
이 부담을 줄여주기 위해 Endpoint를 나누는 Endpoint Slice가 있습니다.

- 실습 코드 배포
수퍼마리오를 배포하면서 Readiness Probe 설정과 NodePort 설정 또 위에서 수행한 externalTrafficPolicy를 Local로 설정해 배포했습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: mario
labels:
app: mario
spec:
replicas: 1
selector:
matchLabels:
app: mario
template:
metadata:
labels:
app: mario
spec:
tolerations:
- key: "node-role.kubernetes.io/control-plane"
effect: "NoSchedule"
nodeSelector:
node-role.kubernetes.io/control-plane: ""
containers:
- name: mario
image: pengbai/docker-supermario
readinessProbe:
exec:
command:
- cat
- healthcheck
---
apiVersion: v1
kind: Service
metadata:
name: mario
spec:
ports:
- name: mario-webport
port: 80
targetPort: 8080
nodePort: 30001
selector:
app: mario
type: NodePort
externalTrafficPolicy: Local
- 생성 확인
$ watch kubectl get pod,svc,ep,endpointslice -owide
눈썰미가 좋은 사람이라면 mario pod가 not ready 상태인 것을 확인하셨을 겁니다.
not ready 상태의 원인은 배포 시 설정한 Readiness probe 설정 때문입니다.
pod 내에 healthcheck라는 파일이 없기 때문에 명령어가 실패했고, 그로인해 pod가 정상적으로 생성되지 않았습니다.
또 생성되지 않은 Pod로 Traffic을 흘려주면 안되기 때문에 Endpoint에서도 객체는 생성되었지만 IP가 제외되어 있는 것을 확인할 수 있습니다.

- healthcheck 파일 생성을 통해 정상화
$ kubectl exec -it deployments/mario -- touch healthcheck
Readiness Probe에 통과되면서 Pod의 Ready와 Endpoint 부여가 완료된 것을 확인하실 수 있습니다.

'Cloud > Kubernetes' 카테고리의 다른 글
| [KANS] Ingress (0) | 2024.10.13 |
|---|---|
| [KANS] LoadBalancer (2) | 2024.10.05 |
| [KANS] Calico 네트워크 모드 (1) | 2024.09.15 |
| [KANS] Calico CNI 기본 통신 (0) | 2024.09.14 |
| [KANS] Flannel CNI (2) | 2024.09.08 |