
어느덧 절반을 했다.
terraform이 생소해서 아직 손에 익지 않았지만 천천히 익숙해질 때까지 해보겠다.
Provider
1. Terraform의 동작 원리
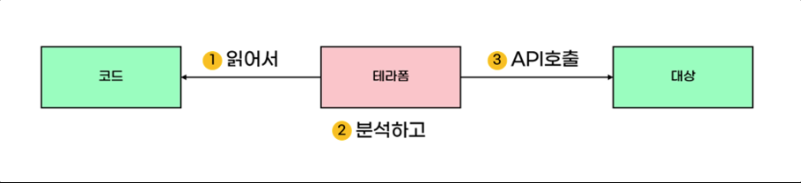
테라폼은 코드를 읽어 코드가 실행이 가능한지 분석하고, 가능하다면 API를 통해 대상에 속성이 반영되도록 호출합니다.
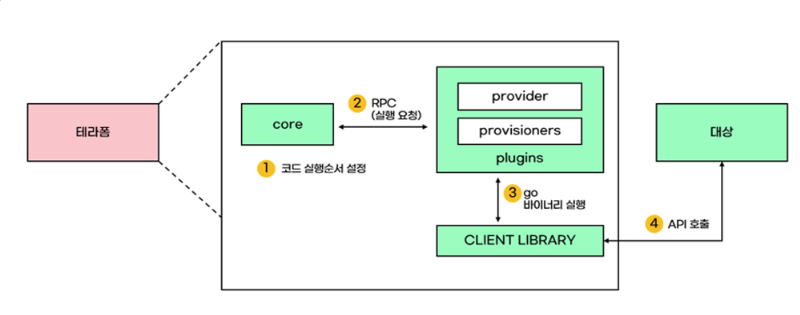
core 컴포넌트는 사용자의 코드에 대해 순서를 작성하고, 플러그인에게 RPC 통해 코드 실행을 요청한다.
플러그인은 go 바이너리를 통해 대상에게 api로 실행을 요청한다.
terraform 코드에서도 required_providers를 선언하므로 어떤 프로바이더를 사용할지를 명시한다.

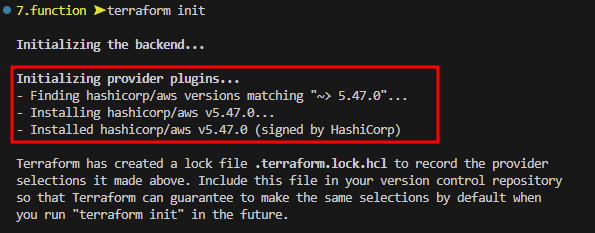
terraform init
명령어를 수행하면 플러그인 (프로바이더) 모듈을 다운로드 받는다.
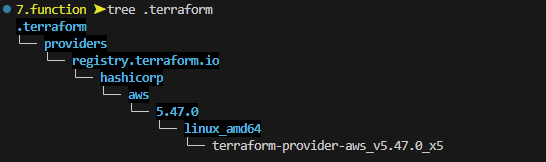
init이 완료되면, .terraform 디렉토리가 생성되는데 내부를 확인해보면 library와 binary가 생성되어 있는 것을 확인할 수 있다.
Terraform 프로바이더 구성
- 로컬 이름과 프로바이더 지정
required_providers 블록 내에 정의된 프로바이더는 로컬 이름 = {} 으로 구성되어 있다.
로컬 이름은 모듈 내에서는 고유해야 하므로 동일한 로컬 이름의 프로바이더를 중복 선언할 수 없다.
예를 들어 http 이름을 사용하는 여러 프로바이더를 사용해야 하는 경우 각 프로바이더의 이름으로 구분하고,
source 영역에 명시적으로 지정해야한다.
(source가 동일한 경우 다수 선언은 불가능하다.)
terraform {
required_providers {
dev-http = {
source = "architect-team/http"
version = "~> 3.0"
}
http = {
source = "hashicorp/http"
}
prod-http = {
source = "terraform-aws-modules/http"
}
}
}
data "http" "example" {
provider = aws-http
url = "https://checkpoint-api.hashicorp.com/v1/check/terraform"
request_header = {
Accept = "applcation/json"
}
}
- 단일 프로바이더의 다중 정의
사용되는 리소스가 리전이나, iam 이 달라 별도로 선언해야 하는 경우, 프로바이더 선언에서 alias를 명시하고,
사용하는 리소스와 데이터 소스에서는 provider 메타인수를 사용해 특정 프로바이더를 지정할 수 있다.
주의 사항은 A-A 구조의 멀티 리전 서비스를 운영할 경우 리전 간 레이턴시, resource ID와 같이 리전이 달라 발생하는
차이점에 대한 고려 사항이 많아 충분한 검토가 필요하다.
또 코드의 편의를 위해 단일 모듈에 멀티 리전의 자원을 관리하는 경우 한개 리전에서 장애가 발생하면,
apply가 실패하므로 각각의 환경을 격리하여 리전 장애에 대한 영향을 최소화한다.
provider "aws" {
region = "ap-southeast-1"
}
provider "aws" {
alias = "seoul"
region = "ap-northeast-2"
}
resource "aws_instance" "test-svr-1" {
ami = "ami-06b79cf2aee0d5c92"
instance_type = "t2.micro"
}
resource "aws_instance" "test-svr-2" {
provider = aws.seoul
ami = "ami-0483306a66170cd99"
instance_type = "t2.micro"
}
배포 후 각 리전 생성 확인
aws ec2 describe-instances --filters Name=instance-state-name,Values=running --output table
aws ec2 describe-instances --filters Name=instance-state-name,Values=running --output table --region ap-southeast-1
- 프로바이더 요구사항 정의
테라폼 실행 시 요구되는 프로바이더 요구사항은 terraform 블록의 required_providers 블록에 여러 개를 정의 할 수 있다.
source에는 프로바이더 다운로드 경로를 지정하고, version은 버전 제약을 명시한다.
terraform {
required_providers {
<프로바이더 로컬 이름> = {
source = [<호스트 주소>/]<네임스페이스>/<유형>
version = <버전 제약>
}
...
}
}
- 호스트 주소 : 프로바이더를 배포하는 주소로 기본값은 registry.terraform.io
- 네임스페이스 : 지정된 레지스트리 내에서 구분하며, 공개된 레지스트리 및 terraform cloud의 비공개 레지스트리의 프로바이더를 게시하는 조직을 의미
- 유형 : 프로바이더에서 관리되는 플랫폼이나 서비스 이름으로 일반적으로 접두사와 일치하나 일부 예외가 있을 수 있음
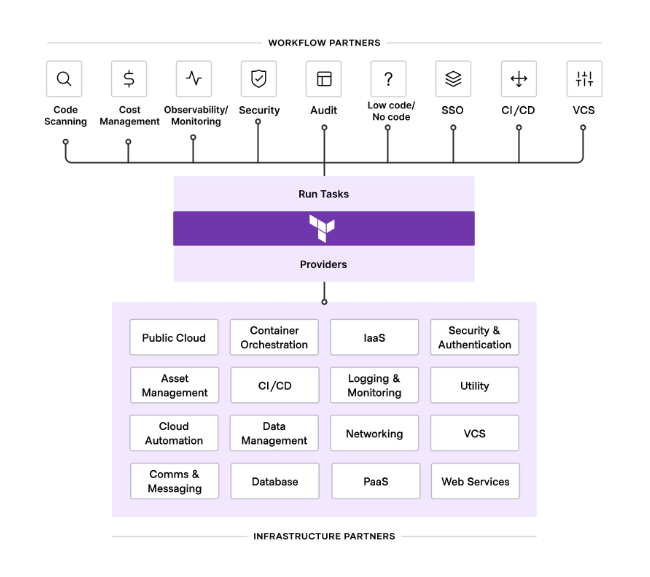
Terraform 에코시스템
테라폼의 에코시스템은 사용자가 사용하는 방식과 구조에 테라폼을 적용할 수 있도록 설계된다.
크게 워크플로우 파트너와 인프라스트럽처 파트너로 나뉘어 있다.
인프라 파트너는 사용자가 테라폼으로 대상 플랫폼의 API로 상호작용 가능한 리소스를 관리할 수 있도록 한다.
Terraform State
Terraform은 멱등성을 보장합니다. 동작 원리에서 작성한 것과 같이 코드 실행 시 API 호출이 바로 수행되는 것이 아니라,
검토 단계가 수행되므로 현재 배포된 자원과 비교하여 달라진 것이 있으면 API를 호출하고, 그렇지 않다면 아무런 변화를 일으키지 않습니다.
이 비교가 이뤄지는 기준 파일이 state 파일입니다.
tfstate 파일은 수동으로 편집하거나, 직접 작성 시 플랫폼과 싱크가 깨져 사용하지 못할 수 있으므로 수동 편집은 하지 않아야 합니다.
테라폼은 잠금 기능을 제공하지 않기 때문에 경합 상황이 발생할 수 있기 때문에 잠금할 수 있도록 3rd party를 통해서라도 관리되어야 합니다.
또, 인프라의 환경이 여러개인 경우라면 state 파일 관리와 동시 작업 시 Locking으로 인한 생산성 저하가 발생하지 않도록,
환경을 구분하여 격리하는 것이 좋습니다.
[유형 별 state 실습]
| 유형 | 구성 리소스 정의(*.tf) | State 구성 데이터 | 실제 리소스 | 기본 예상 동작 |
| 1 | 있음 | 리소스 생성 | ||
| 2 | 있음 | 있음 | 리소스 생성 | |
| 3 | 있음 | 있음 | 있음 | 동작 없음 |
| 4 | 있음 | 있음 | 리소스 삭제 | |
| 5 | 있음 | 동작 없음 |
유형 1 : 신규 리소스 정의 > Apply
locals {
name = "ssungz-test"
}
resource "aws_iam_user" "ssungz-iamuser1" {
name = "${local.name}1"
}
resource "aws_iam_user" "ssungz-iamuser2" {
name = local.name
}

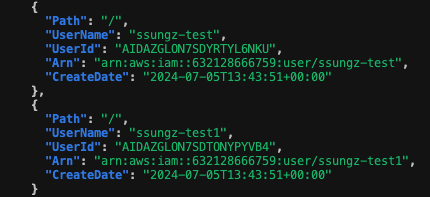
유형 2 : 생성 리소스 수동 제거 > apply
$ aws iam delete-user --user-name ssungz-test
$ aws iam delete-user --user-name ssungz-test
aws cli로 생성한 계정을 수동으로 삭제한 후 Plan을 하면 아래와 같이 계정을 새로 생성한다고 표시된다.
하지만 -refresh=false 옵션을 주면 no change가 표시된다.
refresh=false 옵션을 수행하면 api를 호출해 검토하지 않고, 코드 내에서만 검토가 이뤄진다.
따라서, 코드에서 User 구문을 삭제하지 않았기 때문에 변경 사항이 없는 것으로 인식해 no change가 발생하는 것이다. Docs
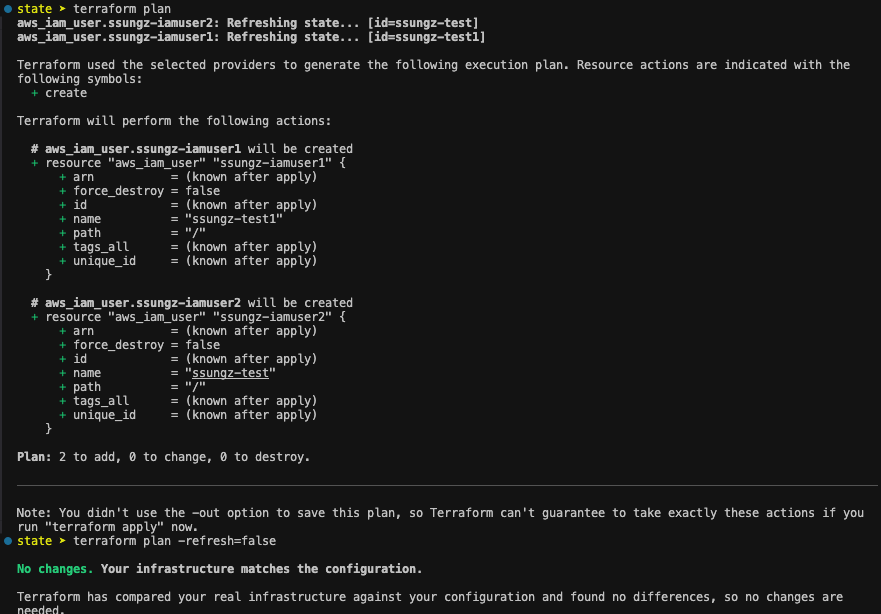
유형 3 : 코드, state, 형상 모두 일치한 경우
apply 수행 시 no change로 변경 사항이 없고, tfstae 파일의 serial도 변경되지 않는다.
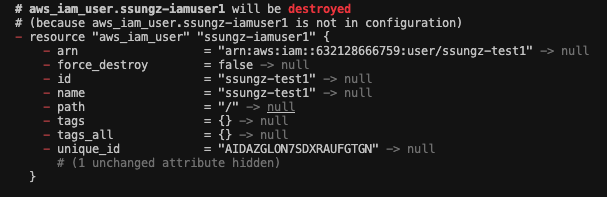
유형 4 : 코드에서 일부 리소스 삭제 > apply
특정 리소스에 대한 구문을 코드에서 삭제하고 배포하면 당연하게도 해당 자원에 대한 Destroy가 발생한다.
locals {
name = "ssungz-test"
}
resource "aws_iam_user" "ssungz-iamuser2" {
name = local.name
}
유형 5 : 실수로 tfstate 파일 삭제 > plan / apply
실제 자원이 있음에도 plan 시 해당 자원을 재생성하겠다는 문구가 발생한다.
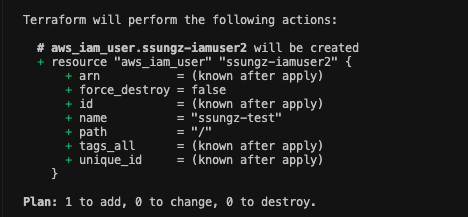
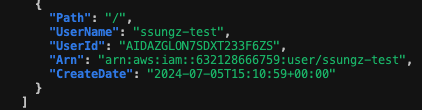
유형 6 : import를 사용하여 tfstate 파일 복구
terrform import 인자 : terraform [global options] import [options] ADDR ID
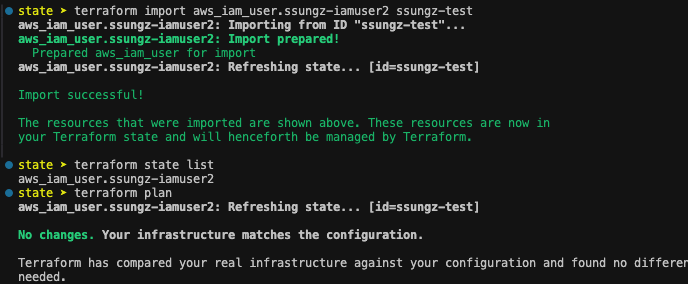
tfstate와 backup 파일까지 모두 삭제했다면, 노가다로 비교해가며 import해 no change가 나올때까지 무한 반복...해야한다.
terraforming 이라는 오픈 소스를 통해 tf 파일 기준으로 state에 export 할수도 있다.
state 파일 일부가 있다면 merge와 overwrite도 가능하다. terraforming
GitHub - dtan4/terraforming: Export existing AWS resources to Terraform style (tf, tfstate) / No longer actively maintained
Export existing AWS resources to Terraform style (tf, tfstate) / No longer actively maintained - dtan4/terraforming
github.com
Terraform Backend : S3 + DynamoDB
state 파일의 관리와 경합이 발생하지 않기 위해서는 locking을 사용해야 한다고 위에 기재했습니다.
여러 관리 방법이 있겠지만 aws 상에서 s3 와 dynamoDB 의 결합으로 해당 기능을 사용할 수 있습니다.
Step 1. S3 생성
$ git clone https://github.com/sungwook-practice/t101-study.git example
$ cd example/state/step3_remote_backend/s3_backend
## terraform.tfvars 파일 수정
bucket_name = "ssungz-hello-tf102-remote-backend"
Step 2. 테라폼 자원 배포 시 "리모트 백엔드 저장소" 설정 사용
vpc의 variable.tf 파일 수정
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.4.0"
}
}
backend "s3" {
# 버킷명 수정
bucket = "ssungz-hello-tf102-remote-backend"
key = "terraform/state-test/terraform.tfstate"
region = "ap-northeast-2"
# dynamodb_table = "terraform-lock"
}
required_version = ">= 1.4"
}
provider "aws" {}
terraform init으로 S3로 configure 설정 확인

배포 후 terraform state와 aws cli로 tfstate 파일이 s3에 생성된 것 확인
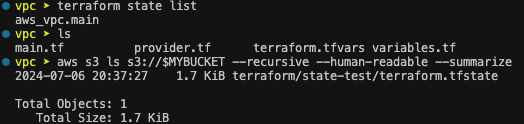
Step 3 DynamoDB 생성
* 테라폼에서 DynamoDB 잠금을 사용하기 위해서는 LockID라는 기본 키가 있는 테이블을 생성해야함.
resource "aws_dynamodb_table" "terraform_state_lock" {
name = "terraform-lock" # table이름
hash_key = "LockID" # key 이름
billing_mode = "PAY_PER_REQUEST"
attribute {
name = "LockID"
type = "S" # key 타입
}
}
배포 후 테이블 생성 확인
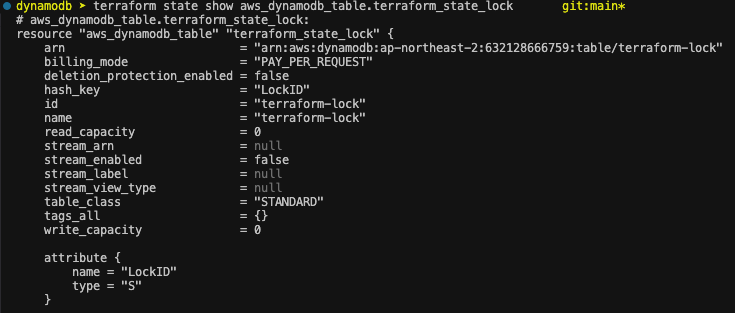
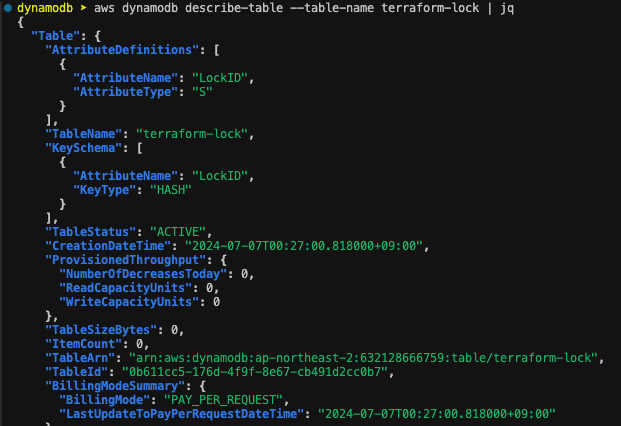
VPC provider.tf에서 "terraform-lock" 라인 주석 해제 후 재배포
backend 설정은 apply가 아니라 init으로 적용해야 합니다.
$ terraform init -migrate-state
terraform apply 입력 대기 상태에서 dynamoDB 확인
콘솔에서 확인 시 LockID 테이블이 생성된 것을 확인
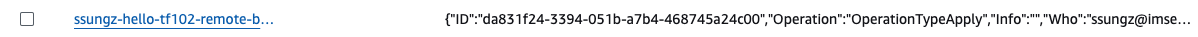
Apply를 진행 후 Item 확인하면 없어진 것을 확인할 수 있습니다.

[S3 버저닝]
S3 정의 시 아래와 같이 버저닝을 Enable 할 경우 배포 시 tfstate 파일의 버전이 변경되어 버전 관리가 가능합니다.
versioning_configuration {
status = "Enabled"
}
}
테라폼 백엔드의 단점은 backend 블록 내에 변수 또는 참조를 사용할 수 없기 때문에,
각 자원의 이름, 리전과 같은 리소스 이름을 코드내에 직접 정의해야 합니다.
부분적으로 구성한 것들을 머지하려면 아래 init 시 추가 옵션을 사용해야 합니다.
$ terraform init -backend-config=backend.hcl
이러한 단점을 보안하기 위해 오픈소스 테라 그런트가 발표되어 사용되고 있습니다.
워크스페이스
워크스페이스는 환경, 조직, 서비스에 따라 구분이 필요할 경우 격리하는 방식이며,
파일 레이아웃을 이용해 격리하는 방법과 terraform에서 제공하는 논리적 격리가 가능합니다.
terraform workspace 를 통한 격리 실습
- ec2 배포
resource "aws_instance" "testsrv1" {
ami = "ami-0ea4d4b8dc1e46212"
instance_type = "t2.micro"
tags = {
Name = "t101-study"
}
}
테스트를 위해 workspace 생성 및 변경 확인

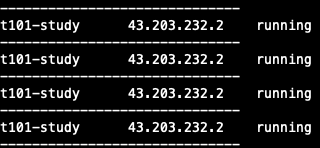
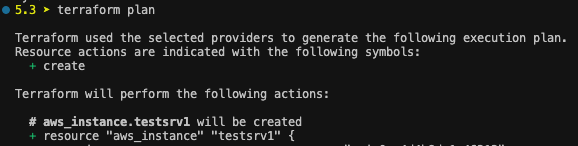
terraform plan 시 인스턴스가 이미 생성되어 있으나, 다시 배포되는 것을 확인할 수 있습니다.
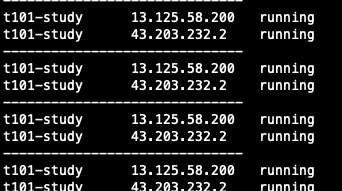
배포 시 동일한 코드로 두개 인스턴스가 running되고 있는 것을 확인할 수 있습니다.
terraform workspace new mywork1 명령어 수행 시 디렉토리가 생겼고,
그 디렉토리의 내부 구조를 보니, mywork1 이라는 디렉토리와 tfstate가 생긴 것을 확인할 수 있습니다.

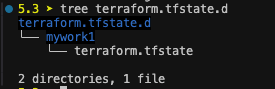
이렇게 동일한 코드로 workspace 별로 자원을 생성할 수 있고, 구분해 관리할 수 있습니다.
파일 레이아웃 격리의 경우 서로 다른 backend를 나누어 관리하기 때문에 강력하게 격리가 가능하고,
state 파일 관리도 용이합니다. 또 환경 별로 리소스의 스펙과 종류를 분기하는 것도 간단합니다.
반대로 terraform workspace의 경우 하나의 모듈에서 각각의 환경에 대한 코드를 동일한 구성으로 프로비저닝 할 수 있지만
state 파일 관리의 어려움, 분기 처리의 어려움이 있어 완벽한 격리는 불가능에 가깝습니다.
'Cloud > Terraform' 카테고리의 다른 글
| [T101] Terraform 101 Study 7주차 (EKS, Karpenter) (0) | 2024.07.27 |
|---|---|
| [T101] Terraform 101 Study 5주차 (Atlantis custom workflow) (1) | 2024.07.12 |
| [T101] Terraform 101 Study 실습(5) - for (1) | 2024.07.03 |
| [T101] Terraform 101 Study 실습(4) - data resource (0) | 2024.07.02 |
| [T101] Terraform 101 Study 실습(3) - AWS 자원 생성 (0) | 2024.07.01 |
어느덧 절반을 했다.
terraform이 생소해서 아직 손에 익지 않았지만 천천히 익숙해질 때까지 해보겠다.
Provider
1. Terraform의 동작 원리
테라폼은 코드를 읽어 코드가 실행이 가능한지 분석하고, 가능하다면 API를 통해 대상에 속성이 반영되도록 호출합니다.
core 컴포넌트는 사용자의 코드에 대해 순서를 작성하고, 플러그인에게 RPC 통해 코드 실행을 요청한다.
플러그인은 go 바이너리를 통해 대상에게 api로 실행을 요청한다.
terraform 코드에서도 required_providers를 선언하므로 어떤 프로바이더를 사용할지를 명시한다.
terraform init
명령어를 수행하면 플러그인 (프로바이더) 모듈을 다운로드 받는다.
init이 완료되면, .terraform 디렉토리가 생성되는데 내부를 확인해보면 library와 binary가 생성되어 있는 것을 확인할 수 있다.
Terraform 프로바이더 구성
- 로컬 이름과 프로바이더 지정
required_providers 블록 내에 정의된 프로바이더는 로컬 이름 = {} 으로 구성되어 있다.
로컬 이름은 모듈 내에서는 고유해야 하므로 동일한 로컬 이름의 프로바이더를 중복 선언할 수 없다.
예를 들어 http 이름을 사용하는 여러 프로바이더를 사용해야 하는 경우 각 프로바이더의 이름으로 구분하고,
source 영역에 명시적으로 지정해야한다.
(source가 동일한 경우 다수 선언은 불가능하다.)
terraform {
required_providers {
dev-http = {
source = "architect-team/http"
version = "~> 3.0"
}
http = {
source = "hashicorp/http"
}
prod-http = {
source = "terraform-aws-modules/http"
}
}
}
data "http" "example" {
provider = aws-http
url = "https://checkpoint-api.hashicorp.com/v1/check/terraform"
request_header = {
Accept = "applcation/json"
}
}
- 단일 프로바이더의 다중 정의
사용되는 리소스가 리전이나, iam 이 달라 별도로 선언해야 하는 경우, 프로바이더 선언에서 alias를 명시하고,
사용하는 리소스와 데이터 소스에서는 provider 메타인수를 사용해 특정 프로바이더를 지정할 수 있다.
주의 사항은 A-A 구조의 멀티 리전 서비스를 운영할 경우 리전 간 레이턴시, resource ID와 같이 리전이 달라 발생하는
차이점에 대한 고려 사항이 많아 충분한 검토가 필요하다.
또 코드의 편의를 위해 단일 모듈에 멀티 리전의 자원을 관리하는 경우 한개 리전에서 장애가 발생하면,
apply가 실패하므로 각각의 환경을 격리하여 리전 장애에 대한 영향을 최소화한다.
provider "aws" {
region = "ap-southeast-1"
}
provider "aws" {
alias = "seoul"
region = "ap-northeast-2"
}
resource "aws_instance" "test-svr-1" {
ami = "ami-06b79cf2aee0d5c92"
instance_type = "t2.micro"
}
resource "aws_instance" "test-svr-2" {
provider = aws.seoul
ami = "ami-0483306a66170cd99"
instance_type = "t2.micro"
}
배포 후 각 리전 생성 확인
aws ec2 describe-instances --filters Name=instance-state-name,Values=running --output table
aws ec2 describe-instances --filters Name=instance-state-name,Values=running --output table --region ap-southeast-1
- 프로바이더 요구사항 정의
테라폼 실행 시 요구되는 프로바이더 요구사항은 terraform 블록의 required_providers 블록에 여러 개를 정의 할 수 있다.
source에는 프로바이더 다운로드 경로를 지정하고, version은 버전 제약을 명시한다.
terraform {
required_providers {
<프로바이더 로컬 이름> = {
source = [<호스트 주소>/]<네임스페이스>/<유형>
version = <버전 제약>
}
...
}
}
- 호스트 주소 : 프로바이더를 배포하는 주소로 기본값은 registry.terraform.io
- 네임스페이스 : 지정된 레지스트리 내에서 구분하며, 공개된 레지스트리 및 terraform cloud의 비공개 레지스트리의 프로바이더를 게시하는 조직을 의미
- 유형 : 프로바이더에서 관리되는 플랫폼이나 서비스 이름으로 일반적으로 접두사와 일치하나 일부 예외가 있을 수 있음
Terraform 에코시스템
테라폼의 에코시스템은 사용자가 사용하는 방식과 구조에 테라폼을 적용할 수 있도록 설계된다.
크게 워크플로우 파트너와 인프라스트럽처 파트너로 나뉘어 있다.
인프라 파트너는 사용자가 테라폼으로 대상 플랫폼의 API로 상호작용 가능한 리소스를 관리할 수 있도록 한다.
Terraform State
Terraform은 멱등성을 보장합니다. 동작 원리에서 작성한 것과 같이 코드 실행 시 API 호출이 바로 수행되는 것이 아니라,
검토 단계가 수행되므로 현재 배포된 자원과 비교하여 달라진 것이 있으면 API를 호출하고, 그렇지 않다면 아무런 변화를 일으키지 않습니다.
이 비교가 이뤄지는 기준 파일이 state 파일입니다.
tfstate 파일은 수동으로 편집하거나, 직접 작성 시 플랫폼과 싱크가 깨져 사용하지 못할 수 있으므로 수동 편집은 하지 않아야 합니다.
테라폼은 잠금 기능을 제공하지 않기 때문에 경합 상황이 발생할 수 있기 때문에 잠금할 수 있도록 3rd party를 통해서라도 관리되어야 합니다.
또, 인프라의 환경이 여러개인 경우라면 state 파일 관리와 동시 작업 시 Locking으로 인한 생산성 저하가 발생하지 않도록,
환경을 구분하여 격리하는 것이 좋습니다.
[유형 별 state 실습]
| 유형 | 구성 리소스 정의(*.tf) | State 구성 데이터 | 실제 리소스 | 기본 예상 동작 |
| 1 | 있음 | 리소스 생성 | ||
| 2 | 있음 | 있음 | 리소스 생성 | |
| 3 | 있음 | 있음 | 있음 | 동작 없음 |
| 4 | 있음 | 있음 | 리소스 삭제 | |
| 5 | 있음 | 동작 없음 |
유형 1 : 신규 리소스 정의 > Apply
locals {
name = "ssungz-test"
}
resource "aws_iam_user" "ssungz-iamuser1" {
name = "${local.name}1"
}
resource "aws_iam_user" "ssungz-iamuser2" {
name = local.name
}
유형 2 : 생성 리소스 수동 제거 > apply
$ aws iam delete-user --user-name ssungz-test
$ aws iam delete-user --user-name ssungz-test
aws cli로 생성한 계정을 수동으로 삭제한 후 Plan을 하면 아래와 같이 계정을 새로 생성한다고 표시된다.
하지만 -refresh=false 옵션을 주면 no change가 표시된다.
refresh=false 옵션을 수행하면 api를 호출해 검토하지 않고, 코드 내에서만 검토가 이뤄진다.
따라서, 코드에서 User 구문을 삭제하지 않았기 때문에 변경 사항이 없는 것으로 인식해 no change가 발생하는 것이다. Docs
유형 3 : 코드, state, 형상 모두 일치한 경우
apply 수행 시 no change로 변경 사항이 없고, tfstae 파일의 serial도 변경되지 않는다.
유형 4 : 코드에서 일부 리소스 삭제 > apply
특정 리소스에 대한 구문을 코드에서 삭제하고 배포하면 당연하게도 해당 자원에 대한 Destroy가 발생한다.
locals {
name = "ssungz-test"
}
resource "aws_iam_user" "ssungz-iamuser2" {
name = local.name
}
유형 5 : 실수로 tfstate 파일 삭제 > plan / apply
실제 자원이 있음에도 plan 시 해당 자원을 재생성하겠다는 문구가 발생한다.
유형 6 : import를 사용하여 tfstate 파일 복구
terrform import 인자 : terraform [global options] import [options] ADDR ID
tfstate와 backup 파일까지 모두 삭제했다면, 노가다로 비교해가며 import해 no change가 나올때까지 무한 반복...해야한다.
terraforming 이라는 오픈 소스를 통해 tf 파일 기준으로 state에 export 할수도 있다.
state 파일 일부가 있다면 merge와 overwrite도 가능하다. terraforming
GitHub - dtan4/terraforming: Export existing AWS resources to Terraform style (tf, tfstate) / No longer actively maintained
Export existing AWS resources to Terraform style (tf, tfstate) / No longer actively maintained - dtan4/terraforming
github.com
Terraform Backend : S3 + DynamoDB
state 파일의 관리와 경합이 발생하지 않기 위해서는 locking을 사용해야 한다고 위에 기재했습니다.
여러 관리 방법이 있겠지만 aws 상에서 s3 와 dynamoDB 의 결합으로 해당 기능을 사용할 수 있습니다.
Step 1. S3 생성
$ git clone https://github.com/sungwook-practice/t101-study.git example
$ cd example/state/step3_remote_backend/s3_backend
## terraform.tfvars 파일 수정
bucket_name = "ssungz-hello-tf102-remote-backend"
Step 2. 테라폼 자원 배포 시 "리모트 백엔드 저장소" 설정 사용
vpc의 variable.tf 파일 수정
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.4.0"
}
}
backend "s3" {
# 버킷명 수정
bucket = "ssungz-hello-tf102-remote-backend"
key = "terraform/state-test/terraform.tfstate"
region = "ap-northeast-2"
# dynamodb_table = "terraform-lock"
}
required_version = ">= 1.4"
}
provider "aws" {}
terraform init으로 S3로 configure 설정 확인
배포 후 terraform state와 aws cli로 tfstate 파일이 s3에 생성된 것 확인
Step 3 DynamoDB 생성
* 테라폼에서 DynamoDB 잠금을 사용하기 위해서는 LockID라는 기본 키가 있는 테이블을 생성해야함.
resource "aws_dynamodb_table" "terraform_state_lock" {
name = "terraform-lock" # table이름
hash_key = "LockID" # key 이름
billing_mode = "PAY_PER_REQUEST"
attribute {
name = "LockID"
type = "S" # key 타입
}
}
배포 후 테이블 생성 확인
VPC provider.tf에서 "terraform-lock" 라인 주석 해제 후 재배포
backend 설정은 apply가 아니라 init으로 적용해야 합니다.
$ terraform init -migrate-state
terraform apply 입력 대기 상태에서 dynamoDB 확인
콘솔에서 확인 시 LockID 테이블이 생성된 것을 확인
Apply를 진행 후 Item 확인하면 없어진 것을 확인할 수 있습니다.
[S3 버저닝]
S3 정의 시 아래와 같이 버저닝을 Enable 할 경우 배포 시 tfstate 파일의 버전이 변경되어 버전 관리가 가능합니다.
versioning_configuration {
status = "Enabled"
}
}
테라폼 백엔드의 단점은 backend 블록 내에 변수 또는 참조를 사용할 수 없기 때문에,
각 자원의 이름, 리전과 같은 리소스 이름을 코드내에 직접 정의해야 합니다.
부분적으로 구성한 것들을 머지하려면 아래 init 시 추가 옵션을 사용해야 합니다.
$ terraform init -backend-config=backend.hcl
이러한 단점을 보안하기 위해 오픈소스 테라 그런트가 발표되어 사용되고 있습니다.
워크스페이스
워크스페이스는 환경, 조직, 서비스에 따라 구분이 필요할 경우 격리하는 방식이며,
파일 레이아웃을 이용해 격리하는 방법과 terraform에서 제공하는 논리적 격리가 가능합니다.
terraform workspace 를 통한 격리 실습
- ec2 배포
resource "aws_instance" "testsrv1" {
ami = "ami-0ea4d4b8dc1e46212"
instance_type = "t2.micro"
tags = {
Name = "t101-study"
}
}테스트를 위해 workspace 생성 및 변경 확인
terraform plan 시 인스턴스가 이미 생성되어 있으나, 다시 배포되는 것을 확인할 수 있습니다.
배포 시 동일한 코드로 두개 인스턴스가 running되고 있는 것을 확인할 수 있습니다.
terraform workspace new mywork1 명령어 수행 시 디렉토리가 생겼고,
그 디렉토리의 내부 구조를 보니, mywork1 이라는 디렉토리와 tfstate가 생긴 것을 확인할 수 있습니다.
이렇게 동일한 코드로 workspace 별로 자원을 생성할 수 있고, 구분해 관리할 수 있습니다.
파일 레이아웃 격리의 경우 서로 다른 backend를 나누어 관리하기 때문에 강력하게 격리가 가능하고,
state 파일 관리도 용이합니다. 또 환경 별로 리소스의 스펙과 종류를 분기하는 것도 간단합니다.
반대로 terraform workspace의 경우 하나의 모듈에서 각각의 환경에 대한 코드를 동일한 구성으로 프로비저닝 할 수 있지만
state 파일 관리의 어려움, 분기 처리의 어려움이 있어 완벽한 격리는 불가능에 가깝습니다.
'Cloud > Terraform' 카테고리의 다른 글
| [T101] Terraform 101 Study 7주차 (EKS, Karpenter) (0) | 2024.07.27 |
|---|---|
| [T101] Terraform 101 Study 5주차 (Atlantis custom workflow) (1) | 2024.07.12 |
| [T101] Terraform 101 Study 실습(5) - for (1) | 2024.07.03 |
| [T101] Terraform 101 Study 실습(4) - data resource (0) | 2024.07.02 |
| [T101] Terraform 101 Study 실습(3) - AWS 자원 생성 (0) | 2024.07.01 |